In this study, we address the problem of learning a posture-controllable three-dimensional (3D) representation of articulated robotic hands. Neural radiance fields (NeRFs) have outperformed grid-like 3D representations on a novel view synthesis tasks; however, rendering novel views while controlling the joints and posture of robotic hands using NeRFs is still challenging. Conventional methods address this problem by explicitly conditioning the posture or by introducing individual part-wise NeRFs. However, they are unable to scale with respect to the number of joints, thereby causing poor convergence or poor rendering performance. Based on the assumption that the difficulty in controllability results from high-dimensional inputs, we propose a NeRF conditioned on a fixed-length and low-dimensional posture representation. Specifically, we employ the eigengrasp representation to control the joints and posture of robotic hands. This strategy is called the eigengrasp-conditioned neural radiance field (Eigengrasp-NeRF). To evaluate the effectiveness of our method, we conduct experiments in which a novel robotic hand dataset that comprises multi-view images with various camera poses and postures is rendered. The experimental results reveal that our method allows the control of joints while maintaining the rendering quality of the original NeRF, outperforming the pose-conditioned NeRF. Moreover, our method generalizes to unknown grasping behaviors when trained on a dataset that covers the grasping taxonomy.
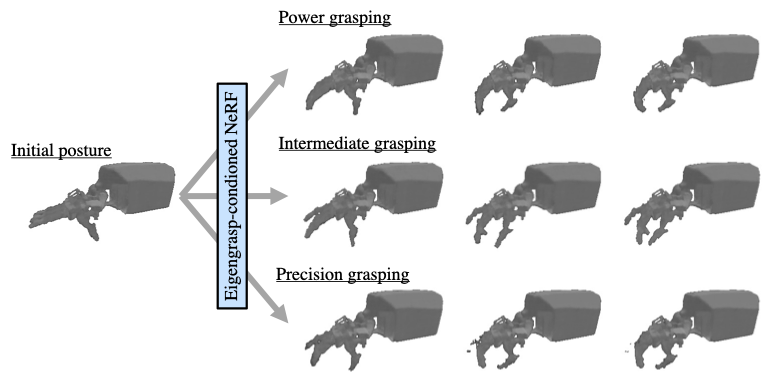
Overview of Eigengrasp-NeRF's rendering quality and its controllability based on grasping taxonomy.
This project is a joint collaboration with Honda R&D.