活性化関数#
活性化関数(activate function) は線形層などの出力
に対して,次のような変換を行う関数である.
一般的に,活性化関数は非線形かつ微分可能である必要があり,ニューラルネットワークの特性やタスクに応じて適切に変更する必要がある.ここでは,代表的な活性化関数であるSigmoid関数,Tanh関数,ReLU関数,Softmax関数について紹介する.
Sigmoid関数#
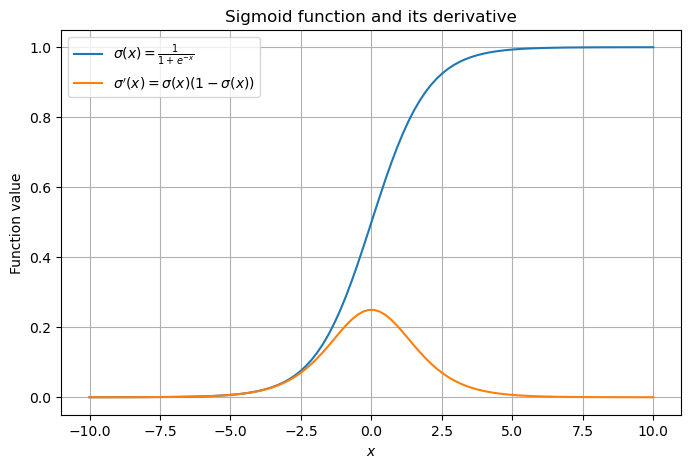
Sigmoid関数 は実数の入力 \(x \in \mathbb{R}\) を次のように変換する.
この関数は出力を常に \(0\) から \(1\) の範囲に制限でき,出力を確率として表現するのに適している.またシグモイド関数は微分可能であることから,後述する勾配ベースの最適化やロジスティック回帰やニューラルネットワーク等との相性が良い.そのシグモイド関数の微分 \(\sigma'(x)\) は次のように与えられる.
これをPyTorchで可視化する.
import torch
import matplotlib.pyplot as plt
def sigmoid(x):
return 1. / (1. + torch.exp(-x))
def sigmoid_derivative(x):
return sigmoid(x) * (1. - sigmoid(x))
x = torch.linspace(-10, 10, 100)
y = sigmoid(x)
d = sigmoid_derivative(x)
plt.figure(figsize=(8, 5))
plt.plot(x.numpy(), y.numpy(), label=r'$\sigma(x)=\frac{1}{1+e^{-x}}$')
plt.plot(x.numpy(), d.numpy(), label=r'$\sigma^{\prime}(x)=\sigma(x)(1-\sigma(x))$')
plt.title(r'Sigmoid function and its derivative')
plt.xlabel(r'$x$')
plt.ylabel('Function value')
plt.legend()
plt.grid(True)
plt.show()
上記の実装をすることなくPyTorchではSigmoid関数がサポートされている.
import torch.nn as nn
x = torch.randn(2)
act = nn.Sigmoid()
y = act(x)
print('x = ')
print(x)
print('y = ')
print(y)
x =
tensor([-0.5912, 0.7107])
y =
tensor([0.3564, 0.6706])
Tanh関数#
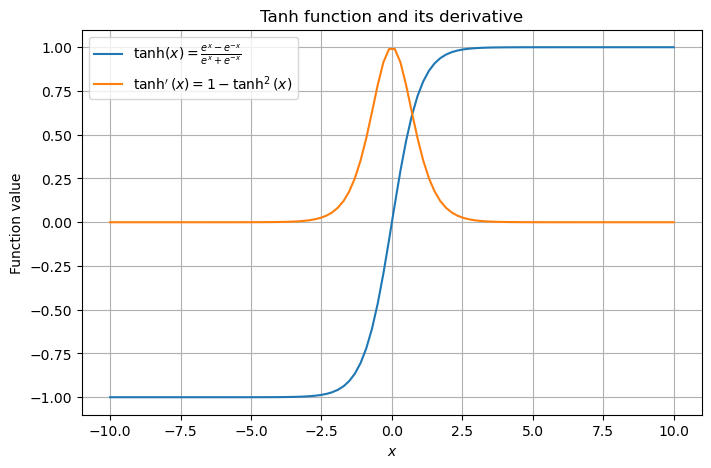
Tanh関数(双曲線正接関数) は,入力 \(x \in \mathbb{R}\) に対して,次のように計算される.
Tanh関数の出力は常に \(-1\) から \(1\) の範囲に収まり,Sigmoid関数とは異なり出力が正負の両方を取りうる.
また,Tanh関数も微分可能であり,その微分 \(\tanh'(x)\) は以下のように表される.
この性質により,Tanh関数も勾配ベースの最適化やニューラルネットワークの活性化関数に利用される.
これをPyTorchで可視化する.Pytorchでは,シンプルにtorch.tanhで計算できる.
import torch
import matplotlib.pyplot as plt
def tanh(x):
return torch.tanh(x)
def tanh_derivative(x):
return 1. - tanh(x)**2
x = torch.linspace(-10, 10, 100)
y = tanh(x)
d = tanh_derivative(x)
plt.figure(figsize=(8, 5))
plt.plot(x.numpy(), y.numpy(), label=r'$\tanh(x)=\frac{e^x - e^{-x}}{e^x + e^{-x}}$')
plt.plot(x.numpy(), d.numpy(), label=r'$\tanh^{\prime}(x)=1-\tanh^2(x)$')
plt.title(r'Tanh function and its derivative')
plt.xlabel(r'$x$')
plt.ylabel('Function value')
plt.legend()
plt.grid(True)
plt.show()
ReLU関数#
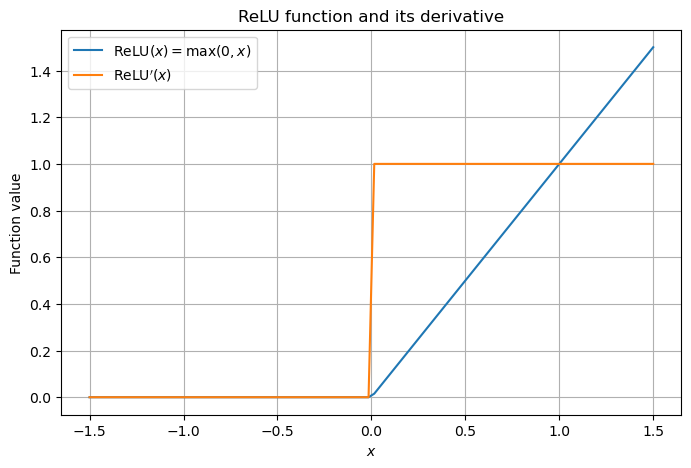
ReLU関数(Rectified Linear Unit, 整流線形関数) は次のように定義される.
ReLU関数は,入力が正の場合は値をそのまま出力し,負の場合は0を出力する.
ReLU関数の微分 \(\text{ReLU}’(x)\) は以下のように表される.
つまり,値を持つときは誤差逆伝播によって流れてくる勾配をそのまま次の層に伝播できる性質を持っており,Sigmoid関数やTanh関数に比べて,ニューラルネットワークを深くしても勾配消失問題が軽減されることが知られている.
これをPyTorchで可視化する.Pytorchではtorch.nn.ReLUでも計算できる.
import torch
import matplotlib.pyplot as plt
def relu(x):
return torch.maximum(torch.tensor(0.0), x)
def relu_derivative(x):
return (x > 0).float()
x = torch.linspace(-1.5, 1.5, 100)
y = relu(x)
d = relu_derivative(x)
plt.figure(figsize=(8, 5))
plt.plot(x.numpy(), y.numpy(), label=r'ReLU$(x) = \max(0, x)$')
plt.plot(x.numpy(), d.numpy(), label=r'ReLU$^{\prime}(x)$')
plt.title(r'ReLU function and its derivative')
plt.xlabel(r'$x$')
plt.ylabel('Function value')
plt.legend()
plt.grid(True)
plt.show()
Softmax関数#
Softmax関数 は多クラス分類問題において,モデルの出力を確率として解釈するために使用される活性化関数である.\(K\) クラスの分類問題において,モデルの出力として得られる各クラスに対応する ロジット(logit) \(\boldsymbol{z} = [z_1, z_2, \dots, z_K]\) の各要素を確率分布に変換することができる.
Softmax関数は入力 \(\boldsymbol{z} \in \mathbb{R}^K\) に対して,次のように定義される:
ここで,\(\exp(z_i)\) はロジットの指数関数を表し,各クラス \(i\) の値を,すべてのクラスの指数の和で正規化することによって,出力が確率分布となる.つまり,
という性質を満たす.
出力 \(y_i = \text{softmax}(z)_i\) に対して,その導関数 \(\frac{\partial y_i}{\partial z_j}\) は次のように表せる.
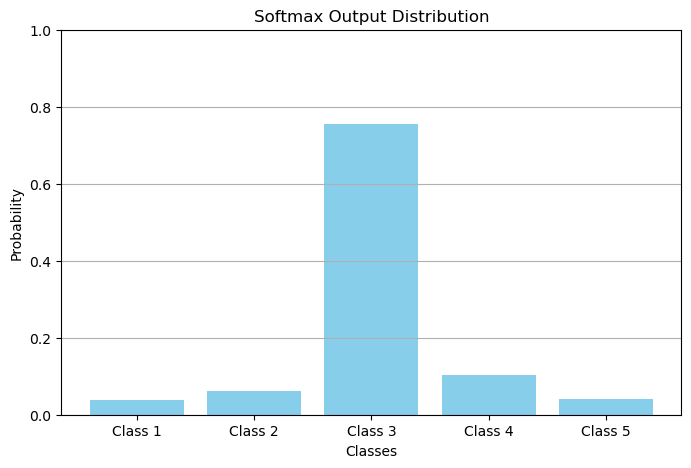
PyTorchのtorch.nn.Softmaxを使ってSoftmaxの出力と総和が1となることを確認する.
logits = torch.tensor([0.01, 0.5, 3.0, 1.0, 0.1])
act = nn.Softmax()
prob = act(logits)
print("Softmax output:", prob)
print("Sum of softmax output:", torch.sum(prob))
classes = [f'Class {i}' for i in range(1, len(logits) + 1)]
plt.figure(figsize=(8, 5))
plt.bar(classes,prob.numpy(), color='skyblue')
plt.title('Softmax Output Distribution')
plt.xlabel('Classes')
plt.ylabel('Probability')
plt.ylim(0, 1)
plt.grid(True, axis='y')
plt.show()
Softmax output: tensor([0.0380, 0.0621, 0.7560, 0.1023, 0.0416])
Sum of softmax output: tensor(1.)
/home/aizawa/miniconda3/envs/ml-py39/lib/python3.9/site-packages/torch/nn/modules/module.py:1532: UserWarning: Implicit dimension choice for softmax has been deprecated. Change the call to include dim=X as an argument.
return self._call_impl(*args, **kwargs)
補足#
多くの活性化関数は torch.nn と torch.nn.functional で定義されている.どちらを使っても良いが,ニューラルネット内部で活性化関数を明示的に定義したい場合などでは,インスタンス化を行う torch.nn を使うと良い.