損失関数#
ニューラルネットワークの学習において,損失関数(loss function) はモデルの予測と実際のラベル(正解値)との誤差を測定する関数である.この誤差を最小化するようにモデルのパラメータを誤差逆伝播法で更新することで,モデルが正解値に近い予測を行えるようになる.そのため,損失関数も微分可能である必要があり,解くタスクに応じて適切に設定する必要がある.
ここでは,回帰のための平均二乗誤差関数(Mean Squared Error),二値分類のための二値交差エントロピー損失関数(Binary Cross Entropy),多クラス分類のための交差エントロピー損失関数(Cross Entropy)について説明する.
平均二乗誤差#
平均二乗誤差(Mean Squared Error, MSE) は,回帰問題において使用される損失関数である.この損失関数は,モデルが予測した値と目標出力値との間の差を二乗して平均を取ったものであり,モデルの予測が正解からどれだけ離れているかを誤差として定量化する.
\(N\) サンプルある場合のMSEを定式化すると,予測値 \(\hat{y}\) と目標出力 \(y\) としたとき
として定義される.MSEを利用する際,タスクに応じて出力の範囲を制限することがある.例えば,0-255の値を持つ画像を出力する場合,目標出力である画素値を0-1の値に正規化したうえで,モデルの出力値は0-1の範囲に収めたいのでSigmoid関数を適用することがある.
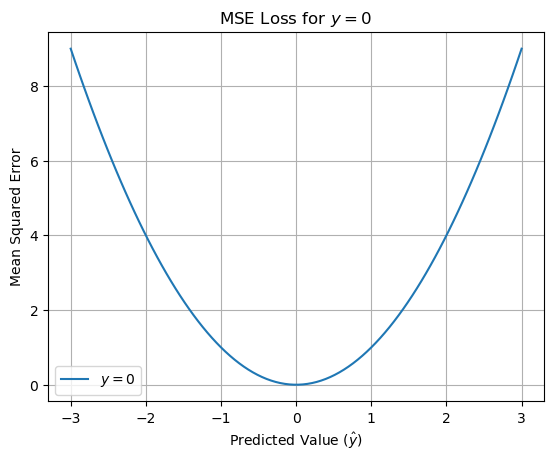
MSEの性質を確認するために,\(N=1\) として目標出力が0の場合におけるMSEの値を可視化する.グラフから見てもわかるように,目標出力と同じ値を出力できたとき,つまり \(\hat{y}=0\),もっとも損失が小さくなっている.
import numpy as np
import matplotlib.pyplot as plt
def mean_squared_error(y, y_hat):
return (y - y_hat) ** 2
y_hat_values = np.linspace(-3, 3, 100)
mse_loss = [mean_squared_error(0, y_hat) for y_hat in y_hat_values]
plt.plot(y_hat_values, mse_loss, label=r"$y = 0$")
plt.xlabel(r"Predicted Value ($\hat{y}$)")
plt.ylabel("Mean Squared Error")
plt.legend()
plt.grid(True)
plt.title(r"MSE Loss for $y=0$ ")
plt.show()
PyTorchでは,torch.nn.MSELoss や torch.nn.functional.mse_loss で実装されているので,プログラムに応じて呼び出せば良い.
import torch
import torch.nn as nn
y_hat = torch.tensor([2.5, 0.0, 2.0])
y = torch.tensor([3.0, -0.5, 2.0])
mse_loss = nn.MSELoss()
loss = mse_loss(y_hat, y)
print(f'Mean Squared Error Loss: {loss.item()}')
Mean Squared Error Loss: 0.1666666716337204
二値交差エントロピー損失関数#
二値交差エントロピー損失関数(Binary Cross Entropy, BCE) は2クラス分類問題において用いられる損失関数である.モデルが予測する確率と実際のラベルとの誤差を測定する.
BCEを定式化すると,パラメータ \(\boldsymbol{\theta}\) を持つモデル \(f\) に入力 \(\boldsymbol{x}\) を与えて得られた予測確率 \(\hat{y} = f(\boldsymbol{x};\boldsymbol{\theta})\) と0または1の確率値が格納されたラベル \(y\) との差を測定する.
\(y\) は予測確率として扱う必要がある,つまり0から1の間にある必要があるために,二値分類を行う際には,損失を計算する前にSigmoid関数を適用することが多い.
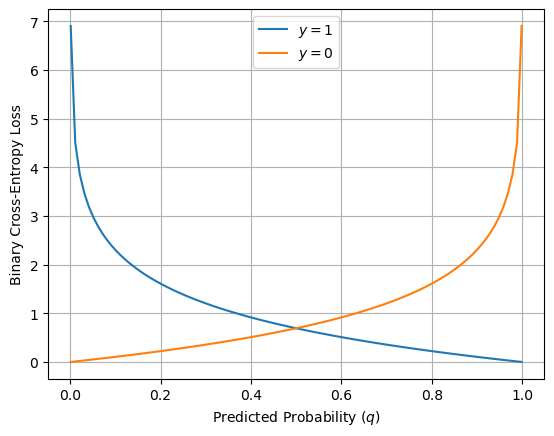
BCEの性質を確認しておく.グラフを見てもわかるように予測確率が実際のラベルに近い場合(例えば,\(y = 1\) のとき \(\hat{y}\) も1に近い),交差エントロピーの値が小さくなることがわかる.一方で,予測確率が間違っている場合(例えば,\(y = 1\) のとき \(\hat{y}\) が0に近い),交差エントロピーの値が大きくなる。
def binary_cross_entropy(y, y_hat):
return -(y * np.log(y_hat) + (1 - y) * np.log(1 - y_hat))
y_hat_values = np.linspace(0.001, 0.999, 100)
cross_entropy_p1 = [binary_cross_entropy(1, y_hat) for y_hat in y_hat_values]
cross_entropy_p0 = [binary_cross_entropy(0, y_hat) for y_hat in y_hat_values]
plt.plot(y_hat_values, cross_entropy_p1, label=r"$y = 1$")
plt.plot(y_hat_values, cross_entropy_p0, label=r"$y = 0$")
plt.xlabel(r"Predicted Probability ($q$)")
plt.ylabel("Binary Cross-Entropy Loss")
plt.legend()
plt.grid(True)
plt.show()
PyTorchでは,torch.nn.BCELoss や torch.nn.functional.binary_cross_entropy で実装されているので,プログラムに応じて呼び出せば良い.
注意点として,yを見てもわかるように複数の予測とラベルが与えられており,PyTorchでは各予測に対するBCEを計算して,その平均を返している.これはニューラルネットワークの学習で用いられるミニバッチ学習を想定した実装となっている.
logits = torch.tensor([1.4, -0.1, 0.8])
y_hat = torch.sigmoid(logits)
print('z=f(x):', logits)
print('y_hat=sigmoid(z):', y_hat)
y = torch.tensor([1.0, 0.0, 1.0])
print('y:', y)
bce_loss = nn.BCELoss()
loss = bce_loss(y_hat, y)
print('bce_loss=', loss)
z=f(x): tensor([ 1.4000, -0.1000, 0.8000])
y_hat=sigmoid(z): tensor([0.8022, 0.4750, 0.6900])
y: tensor([1., 0., 1.])
bce_loss= tensor(0.4120)
交差エントロピー損失関数#
BCEは0か1の2値(2クラス)分類であったのに対して,交差エントロピー損失関数(Cross Entropy, CE) は3クラス以上の多クラス分類問題において用いられる損失関数である.CEも同様にモデルが予測するクラス確率と実際のクラスラベルとの誤差を測定する.
\(K\) クラス分類におけるCEを定式化すると,各クラス \(1, 2, \dots, K\) 対する予測確率 \(\hat{\boldsymbol{y}}\) とクラスラベル \(\boldsymbol{y}\) との誤差を次の式で計算する.
ここで,\(y_i\) はクラス \(i\) の正解ラベルであり,通常はone-hotベクトルで表される.one-hotベクトル とは,正解クラスが1でその他のクラスが0になるベクトルのことを指す.例えば,3クラス分類においてクラス2が正解であれば,one-hotベクトルは次のようになる:
また,\(\hat{y}_i\) は予測確率であるため,Softmax関数 を適用して,出力を確率分布に変換する必要がある.
PyTorchでは,torch.nn.CrossEntropyLoss や torch.nn.functional.cross_entropy で実装されている.これらの関数は,数式とは異なり,関数の内部で Softmax関数の適用やone-hotベクトルへの対応を行うので,入力はSoftmaxを適用する前のロジットとone-hotにする前のインデックスで表記されたクラスラベルのベクトルを与えれば良い.
y = torch.tensor([2])
logits = torch.tensor([[0.01, 0.5, 3.0, 1.0, 0.1]])
ce_loss = nn.CrossEntropyLoss()
loss = ce_loss(logits, y)
print('ce_loss = ', loss)
ce_loss = tensor(0.2797)
補足: 2クラスの場合の交差エントロピー関数#
2クラスの場合,つまりクラス数が \(K=2\) のとき,正解ラベル \(\boldsymbol{y}\) は \([y_1, y_2]\) で,\(y_1 \in \{0, 1\}\) および \(y_2 = 1 - y_1\) と表せる.また予測確率についても,\(\hat{\boldsymbol{y}}\) は \([\hat{y}_1,\hat{y}_2]\) で,\(\hat{y}_2 = 1 - \hat{y}_1\) と表せる.
したがって,このときの交差エントロピーは
であり,2クラスの場合であっても適切に予測の出力を変換すれば交差エントロピー損失を利用しても良い.