Vision Transformer#
Vision Transformer(ViT) は自然言語処理で優れた性能を示し,注目を集めた Transformer の構造をベースにビジョンのために設計されたモデル構造である.ViTの特筆すべき構造は,画像のパッチ埋め込みと自己注意機構(Self-Attention, SA)にある.これらの要素技術は別のノートブックで説明しているので,このノートブックでは Vision Transformer(ViT) の全体像の説明と実装を行う.本実装はtimmのViTの実装を参考にしており,可能な限り,単純化した実装を意識している.
ViTの全体像#
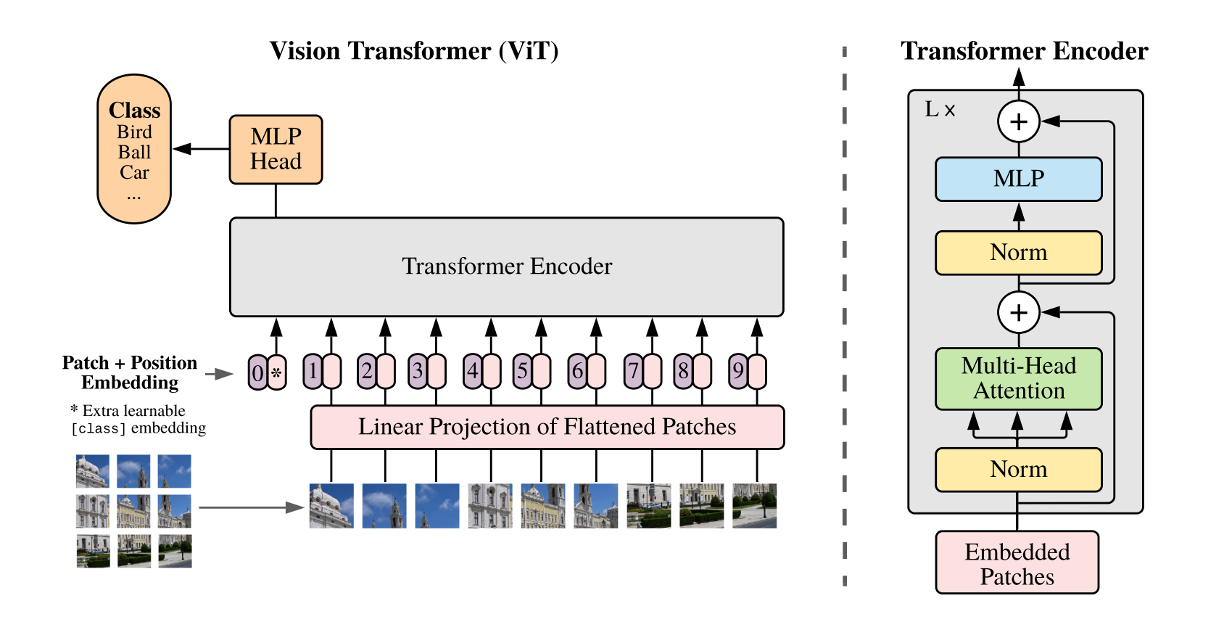
ViTは,画像のパッチ埋め込みと位置埋め込みを行う入力層,Self-Attentionを含む複数のEncoder Block,クラストークンから予測を行うヘッド(head)から構築される.
入力層については別のノートブックで紹介したので,ViTのEncoder Blockを説明する.Encoder Blockは入力トークン x に対して,
class Block(nn.Module):
...
def forward(self, x):
h = self.layer_norm(x)
h = self.attention(h)
h = x + h
h = self.layer_norm(h)
h = self.mlp(h)
h = x + h
return h
と順伝播する.このBlockを複数積み重ねることで深層化する.途中で現れる
h = x + h
は入力をそのまま足し合わせる 残差結合(residual connection) と呼ばれる仕組み(詳しくは別ページ参照)であり,上層からの勾配を減衰させることなく伝播することができる.残差結合は,多層化しても学習が安定する利点がある.
これを実装するために,まずは途中で現れるMLPについて説明する.
MLP Block#
ViTのBlockに含まれるMLPは次のような構造を持つ.
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(dim, hidden_dim)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_dim, dim)
self.drop = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
活性化関数としてReLUではなく Gaussian Error Linear Unit(GELU) を用いている.これはReLUを滑らかにした活性化関数である.また正則化としてDropoutを導入している.
これらの点を除き,基本的な二層のMLPであることがわかる.
Encoder Block#
MLPが定義できたので,次はEncoder Blockを定義する.まずはMulti-Head Self-Attention(MHSA)を定義する.
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self, dim, num_heads=4, dropout=0.5):
super().__init__()
self.head_dim = dim // num_heads
self.num_heads = num_heads
self.proj_q = nn.Linear(dim, dim, bias=False)
self.proj_k = nn.Linear(dim, dim, bias=False)
self.proj_v = nn.Linear(dim, dim, bias=False)
self.proj = nn.Linear(dim, dim, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
bs, num_tokens, dim = x.shape
q = self.proj_q(x)
k = self.proj_q(x)
v = self.proj_q(x)
q = q.reshape(bs, num_tokens, self.num_heads, self.head_dim)
k = k.reshape(bs, num_tokens, self.num_heads, self.head_dim)
v = v.reshape(bs, num_tokens, self.num_heads, self.head_dim)
attn_weight = q @ k.transpose(-2, -1) * dim ** -0.5
attn_weight = F.softmax(attn_weight, dim=-1)
attn_weight = self.dropout(attn_weight)
x = attn_weight @ v
x = x.transpose(1, 2).reshape(bs, num_tokens, dim)
x = self.proj(x)
x = self.dropout(x)
return x
そして,前述した順伝播になるように次のように定義する.
class Block(nn.Module):
def __init__(self, dim, num_heads, dropout):
super().__init__()
self.attn = Attention(dim, num_heads, dropout)
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.mlp = MLP(dim, dim, dropout)
def forward(self, x):
h = self.norm1(x)
h = self.attn(h)
h = x + h
h = self.norm2(h)
h = self.mlp(h)
h = x + h
return h
以上より,オリジナルのViTから省略した機能や引数もあるがシンプルなEncoder Blockが構築できた.
Head#
複数回のBlockを順伝播して得られたクラストークンを入力として受け取り,予測結果を出力するヘッド(head)を作成する.ヘッドはLayer Normと出力次元へ線形変換する線形層から構築される.
つまり,次のようになる.
class Head(nn.Module):
def __init__(self, dim, num_classes):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fc = nn.Linear(dim, num_classes)
def forward(self, x):
x = self.norm(x)
x = self.fc(x)
return x
以上で,ViTの構成要素が定義できた.
Encoder#
では,ViTのEncoderを定義する.Encoder内部でパッチ化を行う実装が多いので,本実装でも画像を受け取る実装とする.まずは,パッチ埋め込みの定義をする.
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=384):
super().__init__()
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x).flatten(2).transpose(1, 2)
return x
実際のBlock数はもっと多いが,ここでは3つのBlcokを持つViTを定義する.
import torch
class ViT(nn.Module):
def __init__(self, img_size, patch_size, in_channels, num_classes, embed_dim, num_heads, dropout):
super().__init__()
self.patch_embed = PatchEmbed(img_size, patch_size, in_channels, embed_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
num_patches = self.patch_embed.num_patches + 1
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
self.block1 = Block(embed_dim, num_heads, dropout)
self.block2 = Block(embed_dim, num_heads, dropout)
self.block3 = Block(embed_dim, num_heads, dropout)
self.head = Head(embed_dim, num_classes)
def forward(self, x):
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.torch.cat((cls_tokens, x), dim=1)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.head(x[:,0])
return x
最後の x[:,0] はクラストークンのみをスライシングしてヘッドに入力している.
モデルをインスタンス化して,ダミーデータで順伝播の検証をしよう.
dummy_x = torch.randn((10, 3, 224, 224))
model = ViT(224, 16, 3, 10, 128, 4, 0.5)
print(model)
y = model(dummy_x)
print('y.shape:', y.shape)
ViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 128, kernel_size=(16, 16), stride=(16, 16))
)
(block1): Block(
(attn): Attention(
(proj_q): Linear(in_features=128, out_features=128, bias=False)
(proj_k): Linear(in_features=128, out_features=128, bias=False)
(proj_v): Linear(in_features=128, out_features=128, bias=False)
(proj): Linear(in_features=128, out_features=128, bias=False)
(dropout): Dropout(p=0.5, inplace=False)
)
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=128, out_features=128, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=128, out_features=128, bias=True)
(drop): Dropout(p=0.5, inplace=False)
)
)
(block2): Block(
(attn): Attention(
(proj_q): Linear(in_features=128, out_features=128, bias=False)
(proj_k): Linear(in_features=128, out_features=128, bias=False)
(proj_v): Linear(in_features=128, out_features=128, bias=False)
(proj): Linear(in_features=128, out_features=128, bias=False)
(dropout): Dropout(p=0.5, inplace=False)
)
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=128, out_features=128, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=128, out_features=128, bias=True)
(drop): Dropout(p=0.5, inplace=False)
)
)
(block3): Block(
(attn): Attention(
(proj_q): Linear(in_features=128, out_features=128, bias=False)
(proj_k): Linear(in_features=128, out_features=128, bias=False)
(proj_v): Linear(in_features=128, out_features=128, bias=False)
(proj): Linear(in_features=128, out_features=128, bias=False)
(dropout): Dropout(p=0.5, inplace=False)
)
(norm1): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=128, out_features=128, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=128, out_features=128, bias=True)
(drop): Dropout(p=0.5, inplace=False)
)
)
(head): Head(
(norm): LayerNorm((128,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=128, out_features=10, bias=True)
)
)
y.shape: torch.Size([10, 10])
エラーなく順伝播が実行でき,意図した (batch_size, num_classes) の出力を得ることができた.