学習と評価#
このノートブックでは,畳み込みニューラルネットワークの学習と評価を行うためのパイプラインを実装する.基本的には,モデル構築とデータセットが異なるのみで,MLPの場合とほぼ同じ手順とコードとなる.
そのため,データセットの作成を中心に学習と評価の説明を行う.
データセットの準備#
画像のデータセットを扱う際,自作データセットを用いない限り,torchvision をインポートして,使用するデータセットのインスタンス化とデータの前処理を含む データ拡張(Data augmentation) の設定を実装すればすぐに利用できる.
このノートブックでは,最もシンプルな画像データセットである MNIST を用いて説明する.まずはMNISTのデータセットの説明を行うために,データ拡張なしで次のようにMNISTのデータセットを作成する.
from torchvision import datasets
train_dataset = datasets.MNIST(root='./data', train=True, download=True)
test_dataset = datasets.MNIST(root='./data', train=False, download=True)
初回実行時はMNISTを root=./data にダウンロードするので時間がかかる.次のセルではデータ数を len 関数で出力しており,正しくダウンロードができていたらデータ数が学習データセットが60,000サンプルで,評価データセットが10,000サンプルと表示されるはずである.
print('train dataset:', len(train_dataset))
print('test dataset:', len(test_dataset))
train dataset: 60000
test dataset: 10000
続いて,インデックスを使ってデータセットからデータを取り出して,入力される画像を確認する.
i = 10
x, y = train_dataset[i]
ここで取得される x は PIL.Image.Image 形式の画像データとなっている.
print('type(x):', type(x))
print('type(y):', type(y))
type(x): <class 'PIL.Image.Image'>
type(y): <class 'int'>
これを一度 numpy形式に変換して,matplotlibで可視化してみる.
import numpy as np
import matplotlib.pyplot as plt
img = np.array(x)
plt.imshow(img, cmap='gray')
plt.title(f'label y: {y}')
plt.axis('off')
(-0.5, 27.5, 27.5, -0.5)

x と y のデータ型からも明らかであるように,CNNへ入力するためには,torch.Tensor 型に変換する必要がある.また次のように img の最小値最大値を見ると,
print('img.min():', img.min())
print('img.max():', img.max())
img.min(): 0
img.max(): 254
となっており,値の範囲が正規化されていない.正規化とデータ型の変換は次の transform を定義して行う.
from torchvision import transforms
transform = transforms.Compose([
transforms.ToTensor(),
])
この transform に PIL.Image.Image 形式の x を与えると,
x = transform(x)
print('type(x):', type(x))
print('x.min():', x.min())
print('x.max():', x.max())
type(x): <class 'torch.Tensor'>
x.min(): tensor(0.)
x.max(): tensor(0.9961)
と,データ型が変換され,最小値と最大値が0から1の範囲に収められていることがわかる.モデルはこのような変換を施した入力を与える必要がある.またこの transform はデータ拡張にも利用することができる.
そして,この transform は次のようにデータセット作成時に渡すことでデータセットクラス内部でこの処理を実行してくれる.
train_dataset = datasets.MNIST(
root='./data', transform=transform, train=True, download=True)
test_dataset = datasets.MNIST(
root='./data', transform=transform, train=False, download=True)
x, y = train_dataset[i]
print('type(x):', type(x))
print('x.min():', x.min())
print('x.max():', x.max())
type(x): <class 'torch.Tensor'>
x.min(): tensor(0.)
x.max(): tensor(0.9961)
データセットの準備ができたので,次は検証データを作成する.PyTorchのデータセットは torch.utils.data.random_split で行える.
import torch
train_size = int(len(train_dataset) * 0.9)
valid_size = int(len(train_dataset) - train_size)
train_dataset, valid_dataset = torch.utils.data.random_split(
train_dataset, [train_size, valid_size])
print(f'train data: {len(train_dataset)}')
print(f'validation data: {len(valid_dataset)}')
print(f'test data: {len(test_dataset)}')
train data: 54000
validation data: 6000
test data: 10000
データローダーを作成する.
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size=128)
valid_loader = DataLoader(valid_dataset, batch_size=100)
test_loader = DataLoader(test_dataset, batch_size=100)
ミニバッチが正しく得られることを確認しておこう.このときの入力サイズが意図しないものだと順伝播時にエラーが生ずるのでダミーデータと同様の形状が得られていることを確認しよう.
for batch in train_loader:
x, y = batch
print(x.shape, y.shape)
break
torch.Size([128, 1, 28, 28]) torch.Size([128])
モデルの構築#
MNISTはグレースケール画像(1チャネル)で0から9までの数字の分類なので,CNNのインスタンス化では in_channels=1 と num_classes=10 を与える.
import torch.nn as nn
class CNN(nn.Module):
def __init__(self, in_channels, num_classes):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 16, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(32)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.gap = nn.AdaptiveAvgPool2d(1)
self.flatten = nn.Flatten()
self.fc = nn.Linear(32, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = nn.functional.relu(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.bn2(x)
x = nn.functional.relu(x)
x = self.pool2(x)
x = self.gap(x)
x = self.flatten(x)
x = self.fc(x)
return x
in_channels = 1
num_classes = 10
model = CNN(in_channels=in_channels, num_classes=num_classes)
GPUでの実行#
深層学習はCPU上で実行すると,MLP程度のスケールなら問題ないが,画像データを扱うCNN程度のスケールとなると,学習の時間が非常に長くなる.ここでは,GPU上で実行する方法を紹介する.
まず,GPUが利用可能な環境化を確認しよう.PyTorchで使用可能なGPUを確認するには,torch.cuda.is_available() と torch.cuda.device_count() を利用するとよい.
if torch.cuda.is_available():
print("GPU is available.")
print(f"Number of available GPUs: {torch.cuda.device_count()}")
for i in range(torch.cuda.device_count()):
print(f"GPU {i}: {torch.cuda.get_device_name(i)}")
else:
print("GPU is not available.")
GPU is available.
Number of available GPUs: 2
GPU 0: NVIDIA RTX A6000
GPU 1: NVIDIA RTX A6000
利用できるならば,次のようにGPUデバイス(device)の設定を行い,モデルをデバイス上に移動させる.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
CNN(
(conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(gap): AdaptiveAvgPool2d(output_size=1)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc): Linear(in_features=32, out_features=10, bias=True)
)
学習・検証ループ#
モデルがGPU上にある場合は,x と y もGPU上に移動させる必要がある.その移動は,
x = x.to(device)
y = y.to(device)
とすれば良い.ここが正しく設定できれば学習・検証・評価のループはMLPのものを再利用できる.
まずはこれを引数とバッチに反映した学習(train_one_epoch)と検証・評価(test)の関数を作成する.
def train_one_epoch(model, loader, loss_function, optimizer, device):
model.train()
train_loss, train_acc = [], []
for batch in loader:
x, y = batch
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
loss = loss_function(output, y)
loss.backward()
optimizer.step()
acc = (output.max(1)[1] == y).float().mean()
train_loss.append(loss.item())
train_acc.append(acc.item())
return np.mean(train_loss), np.mean(train_acc)
def test(model, loader, loss_function, device):
model.eval()
test_loss, test_acc = [], []
with torch.no_grad():
for batch in loader:
x, y = batch
x, y = x.to(device), y.to(device)
output = model(x)
loss = loss_function(output, y)
acc = (output.max(1)[1] == y).float().mean()
test_loss.append(loss.item())
test_acc.append(acc.item())
return np.mean(test_loss), np.mean(test_acc)
そして,学習・検証・評価を含めたループは次のようになる.
from torch import optim
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
epochs = 10
train_loss, train_acc = [], []
valid_loss, valid_acc = [], []
for epoch in range(1, epochs+1):
print(f'Epoch {epoch}/{epochs}')
loss, acc = train_one_epoch(model, train_loader, loss_function, optimizer, device)
print(f'train_loss - {loss:.4f}, train_acc - {acc:.4f}')
train_loss.append(loss)
train_acc.append(acc)
loss, acc = test(model, valid_loader, loss_function, device)
print(f'valid_loss - {loss:.4f}, valid_acc - {acc:.4f}')
valid_loss.append(loss)
valid_acc.append(acc)
print('')
test_loss, test_acc = test(model, test_loader, loss_function, device)
print('test_loss = ', test_loss)
print('test_acc = ', test_acc)
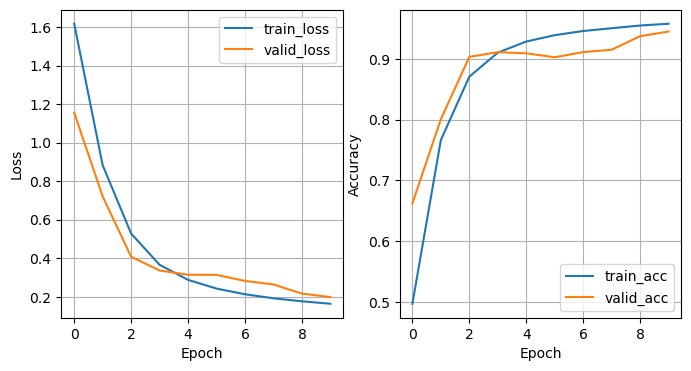
Epoch 1/10
train_loss - 1.6172, train_acc - 0.4970
valid_loss - 1.1551, valid_acc - 0.6622
Epoch 2/10
train_loss - 0.8825, train_acc - 0.7664
valid_loss - 0.7209, valid_acc - 0.8005
Epoch 3/10
train_loss - 0.5280, train_acc - 0.8706
valid_loss - 0.4077, valid_acc - 0.9032
Epoch 4/10
train_loss - 0.3659, train_acc - 0.9101
valid_loss - 0.3365, valid_acc - 0.9108
Epoch 5/10
train_loss - 0.2878, train_acc - 0.9284
valid_loss - 0.3144, valid_acc - 0.9090
Epoch 6/10
train_loss - 0.2426, train_acc - 0.9389
valid_loss - 0.3138, valid_acc - 0.9025
Epoch 7/10
train_loss - 0.2132, train_acc - 0.9457
valid_loss - 0.2823, valid_acc - 0.9110
Epoch 8/10
train_loss - 0.1923, train_acc - 0.9503
valid_loss - 0.2641, valid_acc - 0.9148
Epoch 9/10
train_loss - 0.1765, train_acc - 0.9547
valid_loss - 0.2164, valid_acc - 0.9372
Epoch 10/10
train_loss - 0.1640, train_acc - 0.9577
valid_loss - 0.1987, valid_acc - 0.9448
test_loss = 0.19359830282628537
test_acc = 0.9426999771595002
モデルサイズ,入力サイズ,GPUの性能によってこのセルの実行時間は異なるが10epochほどであればおおよそ数分かかる.損失が下がっていれば,10 epochで90%ほどになるかと思う.
では,予測結果を出力してみよう.
model.eval()
for batch in test_loader:
x, y = batch
x, y = x.to(device), y.to(device)
with torch.no_grad():
output = model(x)
_, prediction = torch.max(output, 1)
fig, axes = plt.subplots(1, 10, figsize=(15, 2))
for i in range(10):
img = x[i].cpu().numpy().squeeze()
axes[i].imshow(img, cmap="gray")
axes[i].set_title(f"Pred: {prediction[i].item()} - GT: {y[i].item()}")
axes[i].axis("off")
plt.tight_layout()
plt.show()
break

予測結果(Pred)と正解(GT)を比較してみると,おおよそ9割程度の正解率であることがわかる.また外観が似た数字間で予測を間違えていることも確認できる.このような可視化からもわかるように,モデルの苦手な予測クラスなどの分析に繋がるので,可視化は必ずしよう.
注意点として,matplotlibの可視化の際に,GPU上にある結果をCPU上に移動させる必要がある.具体的に
img = x[i].cpu().numpy().squeeze()
の部分である.CPUへの移動は .cpu() で行えるので忘れないようにしよう.
モデルの保存#
モデルも忘れずに保存する.保存方法はMLPと同様である.
import os
os.makedirs('output', exist_ok=True)
save_path = 'output/model.pth'
torch.save(model.state_dict(), save_path)
学習結果の表示と保存#
学習曲線の可視化と再現性のためにその値を保存する.こちらもMLPと同様のコードで実行できる.
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.plot(train_loss, label='train_loss')
plt.plot(valid_loss, label='valid_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(train_acc, label='train_acc')
plt.plot(valid_acc, label='valid_acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.show();
np.savetxt('output/train_loss.txt', train_loss)
np.savetxt('output/train_acc.txt', train_acc)
np.savetxt('output/valid_loss.txt', valid_loss)
np.savetxt('output/valid_acc.txt', valid_acc)
注意:
Google Colabで実行している場合,保存したデータを自分のPCにダウンロードする必要がある.ダウンロードは画面左にあるフォルダアイコンをクリックすると保存されているデータが確認できる.各データをダウンロードしておこう.