可視化#
CNNにおいても可視化は重要である.このノートブックでは,学習と評価が終わったCNN再度読み込み,特徴ベクトルの可視化,フィルタの可視化を行い,学習されたモデルを分析する.
モデルの読み込みとデータセットの準備#
まずは評価データセットに対して特徴ベクトルを計算するために,保存したモデルを再度読み込み,評価データセットを作成する.手順はMLPのときと同様である.
import torch
import torch.nn as nn
class CNN(nn.Module):
def __init__(self, in_channels, num_classes):
super(CNN, self).__init__()
self.conv1 = nn.Conv2d(in_channels, 16, kernel_size=3, stride=1, padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.pool1 = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(32)
self.pool2 = nn.MaxPool2d(kernel_size=2, stride=2)
self.gap = nn.AdaptiveAvgPool2d(1)
self.flatten = nn.Flatten()
self.fc = nn.Linear(32, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = nn.functional.relu(x)
x = self.pool1(x)
x = self.conv2(x)
x = self.bn2(x)
x = nn.functional.relu(x)
x = self.pool2(x)
x = self.gap(x)
x = self.flatten(x)
x = self.fc(x)
return x
in_channels = 1
num_classes = 10
model = CNN(in_channels=in_channels, num_classes=num_classes)
save_path = 'output/model.pth'
model.load_state_dict(torch.load(save_path))
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
CNN(
(conv1): Conv2d(1, 16, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn1): BatchNorm2d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(16, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(gap): AdaptiveAvgPool2d(output_size=1)
(flatten): Flatten(start_dim=1, end_dim=-1)
(fc): Linear(in_features=32, out_features=10, bias=True)
)
from torch.utils.data import DataLoader
from torchvision import transforms, datasets
transform = transforms.Compose([
transforms.ToTensor(),
])
test_dataset = datasets.MNIST(
root='./data', transform=transform, train=False, download=True)
test_loader = DataLoader(test_dataset, batch_size=100)
注意:
Google Colabで実行している場合,自分のPCに保存したデータをこのノートブックを実行しているセッションへアップロードする必要がある.アップロードはフォルダアイコンをクリックして保存先を表示させて,そこへダウンロードしたファイルをドラックアンドドロップすればよい.また,アップロードした場合,上記の save_path も忘れずに変更しよう.
特徴ベクトルの可視化#
MLPと同様に特徴ベクトルを可視化する.モデルの定義からもわかるように,モデルの出力はロジットである.今回は全ての評価データセットに対してロジットを計算し,保存したいので評価と予測で行ったときと同じように,forループを作成する.
ロジットとそのラベルの保存にはリストを利用する.手間なのでここでロジットをCPUに移動し,numpy形式で保存しておく.
logits, labels = [], []
model.eval()
for batch in test_loader:
x, y = batch
x, y = x.to(device), y.to(device)
with torch.no_grad():
output = model(x)
logits.append(output.cpu().numpy())
labels.append(y.cpu().numpy())
ロジットのリストをnumpy形式に変換する.
import numpy as np
logits_ = np.array(logits)
print(logits_.shape)
(100, 100, 10)
形状を見てもわかるように,(ループ回数,ミニバッチサイズ,出力次元)というテンソルになっている.これを次のように(ループ回数 * ミニバッチサイズ,出力次元)というように(サンプル数,出力次元)という形状に変換する.
logits_ = logits_.reshape(-1, logits_.shape[2])
logits_.shape
(10000, 10)
また正解ラベルについても(ループ回数,ミニバッチサイズ)となっているので(ループ回数*ミニバッチサイズ,)という形状のベクトルへ変換する.
labels_ = np.array(labels).reshape(-1,)
print(labels_.shape)
(10000,)
ここで特徴ベクトルの可視化をしたいが,10クラス分類のためロジットの出力次元が10であり,MLPのような2次元での可視化ができない.このような場合,PCA や t-SNE などの次元削減手法を用いて,人間が解釈可能な2次元もしくは3次元空間に変換することが一般的である.これらのアルゴリズムの説明と実装は行わないが,利用するだけなら scikit-learn を用いると非常に簡単に利用できる.
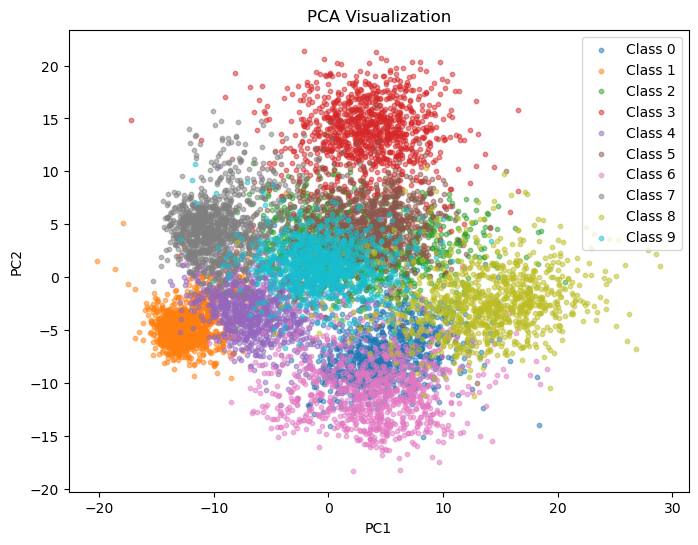
次のセルはPCAによる2次元平面への可視化である.
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
X = logits_
y = labels_
pca = PCA(n_components=2)
X_ = pca.fit_transform(X)
plt.figure(figsize=(8, 6))
u, counts = np.unique(y, return_counts=True)
for y_ in u:
plt.scatter(
X_[y == y_, 0], X_[y == y_, 1],
s=10, label=f'Class {y_}', alpha=0.5)
plt.title("PCA Visualization")
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.legend()
<matplotlib.legend.Legend at 0x152ce5338b20>
次のセルはt-SNEによる2次元平面への可視化である.サンプル数と次元数に応じては数分かかる.
import matplotlib.pyplot as plt
from sklearn.manifold import TSNE
X = logits_
y = labels_
tsne = TSNE(n_components=2)
X_ = tsne.fit_transform(X)
plt.figure(figsize=(8, 6))
u, counts = np.unique(y, return_counts=True)
for y_ in u:
plt.scatter(
X_[y == y_, 0], X_[y == y_, 1],
s=10, label=f'Class {y_}', alpha=0.5)
plt.title("TSNE Visualization")
plt.xlabel("t-SNE1")
plt.ylabel("t-SNE2")
plt.legend()
<matplotlib.legend.Legend at 0x152ce48bfdf0>
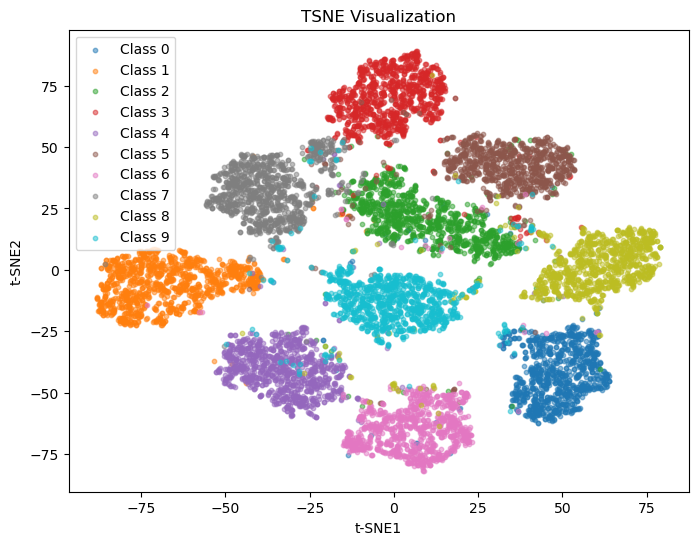
t-SNEの可視化からもわかるように,クラスごとにクラスタが形成され,分類可能な特徴空間が学習できていることがわかる.今回はロジット空間であったが,MLPやCNNの中間層などでもこのような可視化をすると良い.
しかしながら,これらの可視化を過信するのも良くはない.次元削減ということは,特徴ベクトルが持つ情報が損失しており,またクラスタ間の距離やクラスタの大きさは実際のものとは異なる.これらの手法が示すクラスタや距離はあくまで高次元空間を可視化するための近似的な表現であることに注意されたい.
フィルタの可視化#
最初の畳み込み層のフィルタを可視化する.フィルタ(重み)は次のように取得できる.
conv1_filters = model.conv1.weight.data.cpu().numpy()
print(conv1_filters.shape)
print(conv1_filters)
(16, 1, 3, 3)
[[[[ 3.27348799e-01 8.34256061e-05 -3.14952046e-01]
[ 1.75959259e-01 4.06173527e-01 -4.21526939e-01]
[-2.15989634e-01 -2.90302873e-01 -6.98736608e-01]]]
[[[-5.38008511e-01 -2.17403516e-01 -2.73893118e-01]
[-4.21836376e-01 1.72176078e-01 1.63403586e-01]
[-5.17262399e-01 -9.70260948e-02 3.80126685e-01]]]
[[[-5.86986184e-01 2.10951358e-01 2.12535337e-01]
[-6.56695187e-01 3.32558662e-01 1.18912339e-01]
[-6.18945658e-01 -5.77268481e-01 -5.37657559e-01]]]
[[[ 3.42787772e-01 1.80803970e-01 3.72340888e-01]
[-1.43217489e-01 8.07393435e-03 -7.67317936e-02]
[-4.31518853e-01 -2.90887982e-01 -3.20137441e-01]]]
[[[ 4.35855865e-01 3.42363954e-01 -6.48623109e-01]
[-3.86787593e-01 3.48926693e-01 -1.26259103e-01]
[-4.64590043e-01 2.29158346e-02 4.12187964e-01]]]
[[[ 8.26749384e-01 -2.32172295e-01 -6.17797077e-01]
[ 2.08253711e-01 -2.12803796e-01 -1.36967106e-02]
[ 1.06757064e-03 1.70537829e-02 1.84699163e-01]]]
[[[-3.49779963e-01 -4.91822213e-01 2.31314912e-01]
[ 3.55932564e-01 -2.72057980e-01 -4.54167239e-02]
[ 2.22579002e-01 -3.56802016e-01 -1.92610741e-01]]]
[[[ 6.15130402e-02 -1.57622546e-01 -4.11115825e-01]
[ 3.57493818e-01 -2.20217720e-01 -3.00070435e-01]
[-1.13468662e-01 -3.42371732e-01 -2.05188602e-01]]]
[[[ 2.94549376e-01 1.86315045e-01 -5.68974912e-01]
[-5.19551616e-03 -3.65827233e-01 -8.41222107e-02]
[-6.49318397e-01 -8.58798809e-03 7.06952997e-03]]]
[[[-2.64027566e-01 -1.62962630e-01 -2.27171078e-01]
[ 2.83835262e-01 1.24929301e-01 -3.99548888e-01]
[-1.50505245e-01 -2.62139976e-01 -1.09041095e-01]]]
[[[-3.92461985e-01 -2.33807653e-01 3.72342408e-01]
[ 7.44908899e-02 3.01117569e-01 3.39382626e-02]
[ 2.87935853e-01 -4.59268242e-02 -1.74244896e-01]]]
[[[ 7.49697015e-02 3.42632204e-01 -2.73782730e-01]
[ 1.87178459e-02 1.32897452e-01 -2.40054950e-02]
[ 1.67929441e-01 -6.83116853e-01 4.41605389e-01]]]
[[[-7.76346564e-01 -4.48066741e-03 4.64908510e-01]
[-5.82554340e-02 6.34771809e-02 1.44803330e-01]
[-2.24625260e-01 -6.35422766e-02 -4.91137296e-01]]]
[[[-6.15823507e-01 -4.47140604e-01 -2.79340059e-01]
[ 2.52274662e-01 8.32603648e-02 -5.71160555e-01]
[ 1.72861338e-01 2.33451501e-01 -4.45635259e-01]]]
[[[-7.43502438e-01 -3.37694138e-01 -3.44614983e-01]
[-9.15520340e-02 1.96478680e-01 -3.95194024e-01]
[ 1.49485782e-01 1.69822603e-01 2.55972534e-01]]]
[[[ 2.36922994e-01 -7.43128434e-02 1.94104522e-01]
[-8.52329955e-02 -1.66062683e-01 -5.66956550e-02]
[ 3.24752182e-01 1.40203655e-01 3.33678484e-01]]]]
最初の畳み込み層(conv1)は入力チャネルが1,出力チャネルが16,フィルタサイズが3なので,フィルタの形状が(16, 1, 3, 3) となっている.この畳み込み層には16枚のフィルタがあるのでこれを全て可視化する.
filters = conv1_filters
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
fig.suptitle("Convolution Filters (16 filters of size 3x3)")
for i, ax in enumerate(axes.flat):
filter_2d = filters[i, 0]
img = ax.imshow(filter_2d, cmap='gray')
ax.axis('off')
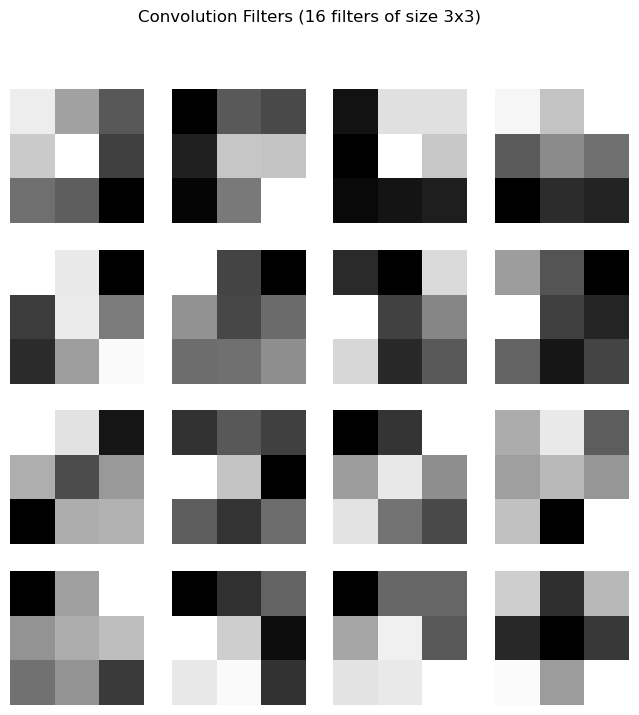
特徴マップの可視化#
入力が画像ということもあり,特徴マップの可視化は重要である.test_datasetから取り出した画像を一枚順伝播したとき,上記で可視化したフィルタを適用するとどのような特徴マップが得られるかを可視化しよう.
中間層で計算される特徴マップを取得するもっとも簡単な方法は output に加えて,その特徴マップを return することであるが,今回はフックというPyTorchの機能を使って取得する.
この機能は次のように register_forward_hook を用いて,指定の層の特徴マップを取得する.
feature_maps = []
def hook_function(module, input, output):
feature_maps.append(output)
model.conv1.register_forward_hook(hook_function)
for batch in test_loader:
x, _ = batch
x = x.to(device)
with torch.no_grad():
_ = model(x)
break
これを実行すると,feature_maps 内に特徴マップが保存される.形状を確認すると,(ミニバッチサイズ,出力チャネル,幅,高さ)である.
feature_maps[0].shape
torch.Size([100, 16, 28, 28])
この特徴マップの最初のサンプルの特徴マップを取得し,フィルタと同様の方法で可視化する.
feature_map = feature_maps[0][0]
fig, axes = plt.subplots(4, 4, figsize=(8, 8))
fig.suptitle("Feature Maps from Conv1 Layer")
for i, ax in enumerate(axes.flat):
feature_map_2d = feature_map[i].cpu().detach().numpy()
ax.imshow(feature_map_2d, cmap='gray')
ax.axis('off')

結果からもわかるように,様々な特徴が強調または抑制された特徴マップが可視化できる.一般的なCNNのモデルはチャネル数も膨大で,Poolingによって低解像度化されるため,入力画像のどこを着目しているかをこれらの可視化から解釈することは難しい.しかしながら,バグチェックも含め,このような可視化は重要であるので必要な場面では確認されたい.
Saliency Map#
Saliency Mapはあるクラスに対応するロジットに対して入力の勾配を計算することで,その値を大きく変化させる画素を可視化する手法である.入力に対する勾配を計算する必要があるので,入力 x に対して,x.requires_grad = True を指定する.そして,予測クラスの特徴次元に対して逆伝播を実行する.得られた勾配の絶対値をmin-max正規化してSaliency Mapとする.
loss_function = nn.CrossEntropyLoss()
for batch in test_loader:
x, y = batch
x, y = x.to(device), y.to(device)
x, y = x[0].unsqueeze(0), y[0]
x.requires_grad = True
model.zero_grad()
output = model(x)
prediction = output.argmax(dim=1).item()
output[0, prediction].backward()
grad = x.grad.data.cpu()
smap = grad.abs().numpy()
smap = (smap - smap.min()) / (smap.max() - smap.min())
break
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.imshow(x.cpu().detach().numpy().reshape(28, 28), cmap='gray')
plt.title(f'Input Image')
plt.axis('off')
plt.subplot(1, 2, 2)
plt.imshow(smap.squeeze(), cmap='hot')
plt.title(f"Saliency Map for Predicted Class {prediction}")
plt.axis("off")
plt.show()
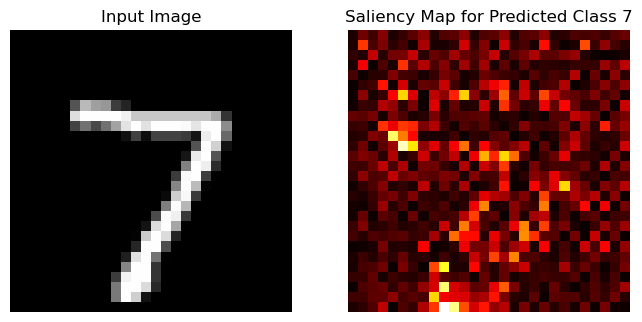
値が大きい画素は7の予測値を大きく変化させる画素であることを示す.結果からもわかるように,7の形がぼんやりと浮かび上がっていることがわかる.さらに良い可視化を得る手法としてGradCAMがあるので興味がある方は調べることをお勧めする.