確率的勾配降下法#
ニューラルネットワークを学習するとは,入力値から正解値に近い予測をするようにニューラルネットワークのパラメータを更新することである.その予測と正解のズレ(誤差)は損失関数によって定量化され,このズレを小さくするパラメータを求めることが目的となる.
しかしながら,非線形関数を含み,パラメータが膨大なニューラルネットワークにおいて,損失関数を最小にするパラメータを解析的に求めることはできない.
そこで,このノートブックでは,ニューラルネットワークでは損失関数を最小化するために,その関数の勾配を利用して,パラメータを更新していく勾配降下法を使う.
勾配降下法によるパラメータ更新#
ここではパラメータ \(\boldsymbol{\theta}\in\mathbb{R}^{D}\) について,損失関数 \(\ell(\boldsymbol{\theta})\) を最小にするパラメータ \(\boldsymbol{\theta}^\ast\) を求めたい.これは
と書くことができる.
勾配降下法(Gradient Descent) はこのパラメータ \(\boldsymbol{\theta}^\ast\) を反復的な更新から求めるアルゴリズムである.反復をパラメータの更新回数 \(t=0,1,2,...\) で,そのときのパラメータ \(\boldsymbol{\theta}^{(t)}\) とする.このとき,勾配降下法は次のように定式化できる.
このとき \(\eta\) は更新幅を定める 学習率(Learning Rate) と呼ばれるパラメータであり,\(\nabla \ell\left(\boldsymbol{\theta}^{(t)}\right)\) は \(t\) ステップ目の損失関数のパラメータに対する勾配である.勾配は損失関数をパラメータで偏微分したものであった.
つまりは勾配の逆方向に従ってパラメータを更新すると損失関数を最小とするパラメータが得られるという話である.
多変数関数での最適化#
ニューラルネットワークを扱う前に,まずは次の関数の最小値を勾配降下法で求める.
ここでは変数を \(x\) としているがニューラルネットワークの場合はパラメータ \(\theta\) となる.
最小値を求める関数を作成する.
alpha = 4.0
f = lambda x: (x[0] ** 2 + alpha * x[1] ** 2) / 2.0
続いて,関数に具体的な値(初期値)を与えて関数の値を計算する.このとき,requires_grad=True は勾配を計算するための引数である.
import torch
x = torch.tensor([0.9, 0.3], requires_grad=True)
関数の最小値を求めるときは,微分可能な関数である場合,その関数の導関数が0となる変数を求めればよかった.そこで,損失関数を関数そのものとしてPyTorchの自動微分機能から損失関数(関数の出力)に関する入力変数 x の勾配を計算する.勾配の計算は .backward() を実行すれば良い.
y = f(x)
y.backward()
勾配は .gradで得られる.
x.grad
tensor([0.9000, 1.2000])
勾配計算ができたので,今回の例における勾配降下法
は,次のように実装できる.
x -= lr * x.grad
が,PyTorchでは torch.optim.SGD というクラスで確率的勾配降下法が最適化手法(Optimizer)としてサポートされているのでこれを利用する.
このSGDはニューラルネットワークの構築時と同様にインスタンス化する必要があり,最適化したい変数のリストと学習率 lr を指定する.
from torch import optim
optimizer = optim.SGD([x], lr=0.1)
この方法を利用した場合は次のステップでパラメータの更新を行う.
optimizer.zero_grads()による勾配の初期化.backwardによる勾配計算optimizer.step()によるパラメータの更新
以上のステップを含めたパラメータの最適化全体を次のセルに実装した.
import torch
from torch import optim
alpha = 4.0
f = lambda x: (x[0] ** 2 + alpha * x[1] ** 2) / 2.0
x = torch.tensor([0.9, 0.3], requires_grad=True)
optimizer = optim.SGD([x], lr=0.1)
path = [x.detach().numpy().copy()]
for i in range(30):
optimizer.zero_grad()
y = f(x)
y.backward()
optimizer.step()
path.append(x.detach().numpy().copy())
最適化の過程はリストに保存しているが,その際に行っている x.detach().numpy().copy() という処理は requires_grad=True としている勾配計算のための変数であり,可視化の際には勾配の計算は不要なので切り離し,PyTorchのTensorクラスの変数をNumpy形式に変換している.そして,最適化の過程でxが更新されるため,同一のxを参照しないようにcopyする.
最後に,リストに保存していた最適化の過程をmatplotlibで可視化しよう
import numpy as np
import matplotlib.pyplot as plt
path = np.array(path)
x_1 = np.linspace(-0.3, 1, 100)
x_2 = np.linspace(-0.6, 0.6, 100)
v, u = np.meshgrid(x_1, x_2)
z = f([v, u])
fig, ax = plt.subplots()
contour = ax.contourf(v, u, z, levels=15, alpha=0.6)
ax.plot(path[:, 0], path[:, 1], marker='o', color='black')
ax.set_xlabel(r'$x_1$')
ax.set_ylabel(r'$x_2$')
ax.set_title('Gradient Descent Optimization')
plt.show()
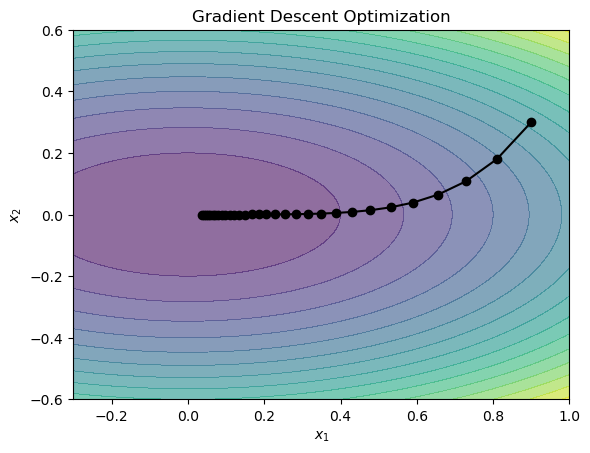
最小解 \((0,0)\) に x が近づいていくことがわかる.
二変数関数なので何をしているかイメージがつかないかもしれないが,やっていることは「関数の最小値を求めるために,関数の傾き(勾配)が0となる点(パラメータ)を探している」ことに他ならない.受験数学や線形回帰における正規方程式などでは,各データ点に対して,勾配が0となる連立方程式をたてて,これを解析的に解いているが,勾配法はこれを反復的に解いているだけである.
MLPの勾配計算とパラメータ更新の実行#
勾配降下法は局所解に陥りやすく,深層学習のような膨大なパラメータを持つニューラルネットワークを大規模なデータセットから学習するために,勾配降下法を利用することは,メモリ的に非現実的である.そこで損失関数を全サンプルから計算するのではなくランダムにサンプリングした部分集合 \(\mathcal{B}\) から計算する勾配法が利用される.\(t\) ステップ目の部分集合を \(\mathcal{B}^{(t)}\) としたとき損失関数は以下のように書ける.
このとき,\(\left|\mathcal{B}^{(t)}\right|\) は部分集合に含まれるサンプル数を示す.\(\left|\mathcal{B}^{(t)}\right|=1\) またはサンプル数が小さい値のとき 確率的勾配降下法(Stochastic Gradient Descent) と呼ばれる.確率的勾配降下法は特にニューラルネットワークの学習などパラメータ数 \(D\) が多いとき局所解の回避だけでなく計算効率的な側面から見ても全サンプルを利用する勾配降下法と比較して効果的である.
構築したMLPで勾配計算とパラメータ更新を行う.まずMLPの作成とダミーデータの作成を行う.
import torch
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MLP, self).__init__()
self.layer_in = nn.Linear(input_dim, hidden_dim)
self.layer_hidden = nn.Linear(hidden_dim, hidden_dim)
self.layer_out = nn.Linear(hidden_dim, output_dim)
self.act = nn.ReLU()
self.act_out = nn.Sigmoid()
def forward(self, x):
h = x
h = self.layer_in(h)
h = self.act(h)
h = self.layer_hidden(h)
h = self.act(h)
h = self.layer_out(h)
h = self.act_out(h)
return h
model = MLP(input_dim=3, hidden_dim=32, output_dim=1)
input_size = (1, 3)
dummy_input = torch.randn(*input_size)
続いて,最適化関数を設定する.多変数関数の例とは異なり,SGDによって学習されるパラメータはMLPを構成する線形層のパラメータ全てである.これらをまとめて取得するには,model.parameters() を利用すると良い.
optimizer = optim.SGD(model.parameters())
そして,二乗誤差関数の設定をする.全体の学習用コードは次の資料で説明するので,ここでは,MLPにおける勾配計算と更新方法を確認するために,適当な入力から出力が0に近づくような平均二乗誤差関数を損失関数として設定する.つまり,サンプル数(ミニバッチ数)\(N=1\) で,MLPの予測値 \(\hat{y}\) と目標出力 \(y=0\) とした
を損失(loss)として計算する.
y_hat = model(dummy_input)
y = torch.tensor([[0.0]])
mse_loss = nn.MSELoss()
loss = mse_loss(y_hat, y)
print('y_hat:', y_hat)
print('y:', y)
print('loss =', loss.item())
y_hat: tensor([[0.5714]], grad_fn=<SigmoidBackward0>)
y: tensor([[0.]])
loss = 0.3264841139316559
計算された損失からパラメータに関する勾配を求める..backward()の実行までを行う.optimizer.zero_grad()を忘れずに呼び出し,勾配を初期化してから勾配計算する必要があることに注意されたい.
optimizer.zero_grad()
loss.backward()
練習として,各層の勾配も出力しておこう.ただし,すべてのパラメータの勾配を可視化すると全部で数千個の値が出力されてしまうので,勾配を持つ層のみ,勾配の形状のみを出力している.
for name, param in model.named_parameters():
if param.grad is not None:
print(f"Layer: {name}, Gradient: {param.grad.shape}")
else:
print(f"Layer: {name} has no gradient")
Layer: layer_in.weight, Gradient: torch.Size([32, 3])
Layer: layer_in.bias, Gradient: torch.Size([32])
Layer: layer_hidden.weight, Gradient: torch.Size([32, 32])
Layer: layer_hidden.bias, Gradient: torch.Size([32])
Layer: layer_out.weight, Gradient: torch.Size([1, 32])
Layer: layer_out.bias, Gradient: torch.Size([1])
パラメータの更新は optimizer.step() を実行すればよかった.パラメータの値が変わっているかを確認するために,更新前後のパラメータの値を torch.equal で比較してみる.
params_before_update = {name: param.clone() for name, param in model.named_parameters()}
optimizer.step()
for name, param in model.named_parameters():
if not torch.equal(param, params_before_update[name]):
print(f"Parameter '{name}' has been updated.")
else:
print(f"Parameter '{name}' has not been updated.")
Parameter 'layer_in.weight' has been updated.
Parameter 'layer_in.bias' has been updated.
Parameter 'layer_hidden.weight' has been updated.
Parameter 'layer_hidden.bias' has been updated.
Parameter 'layer_out.weight' has been updated.
Parameter 'layer_out.bias' has been updated.
値が変わっていることが確認できた.最後に,optimizer.zero_grad()の挙動も確認しておこう.ここのセルまで順番に正しく実行しているのならば,以下のセルを実行してもわかるように,各層のパラメータには勾配が保存されている.
for name, param in model.named_parameters():
if param.grad is not None:
print(f"Layer: {name}, Gradient: {param.grad.shape}")
else:
print(f"Layer: {name} has no gradient")
Layer: layer_in.weight, Gradient: torch.Size([32, 3])
Layer: layer_in.bias, Gradient: torch.Size([32])
Layer: layer_hidden.weight, Gradient: torch.Size([32, 32])
Layer: layer_hidden.bias, Gradient: torch.Size([32])
Layer: layer_out.weight, Gradient: torch.Size([1, 32])
Layer: layer_out.bias, Gradient: torch.Size([1])
optimizer.zero_grad()を呼び出してから再度実行してみる.
optimizer.zero_grad()
for name, param in model.named_parameters():
if param.grad is not None:
print(f"Layer: {name}, Gradient: {param.grad.shape}")
else:
print(f"Layer: {name} has no gradient")
Layer: layer_in.weight has no gradient
Layer: layer_in.bias has no gradient
Layer: layer_hidden.weight has no gradient
Layer: layer_hidden.bias has no gradient
Layer: layer_out.weight has no gradient
Layer: layer_out.bias has no gradient
no gradient と表示されていることからもわかるように,勾配の情報が初期化されていることがわかる.
ここまでの処理からもわかるようにニューラルネットワークのパラメータの一回の更新はここまでの
optimizer.zero_grad()による勾配の初期化順伝播の実行と損失の計算
.backwardによる勾配計算optimizer.step()によるパラメータの更新
という一連の処理のことを示し,この処理の単位を,iterationという.
実際にはこの更新処理を複数iteration回実行する.もしくは,データセットに含まれるデータ全てを使って更新した回数 epoch として,複数epoch学習することで,最適なモデルのパラメータを求める.