可視化#
このノートブックでは,学習と評価が終わったMLPと学習結果を再度読み込み,学習曲線の可視化,識別境界の可視化,重みの分布の可視化,勾配の可視化を行い,学習されたモデルを分析する.
学習曲線の可視化#
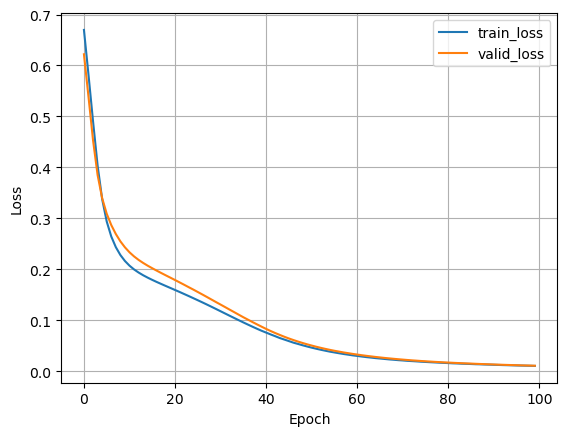
損失と精度の推移を示す学習曲線から過学習等の学習の状況が確認できるため,ニューラルネットワークの学習時は必ず可視化しよう.まずは保存した.txtから損失と精度を読み出す.numpyを用いた場合,loadtxt関数を利用すると良い.
import numpy as np
train_loss = np.loadtxt('output/train_loss.txt')
train_acc = np.loadtxt('output/train_acc.txt')
valid_loss = np.loadtxt('output/valid_loss.txt')
valid_acc = np.loadtxt('output/valid_acc.txt')
読み出せたので,これをmatplotlibを使って可視化する.
import matplotlib.pyplot as plt
plt.plot(train_loss, label='train_loss')
plt.plot(valid_loss, label='valid_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.show();
plt.plot(train_acc, label='train_acc')
plt.plot(valid_acc, label='valid_acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.show();
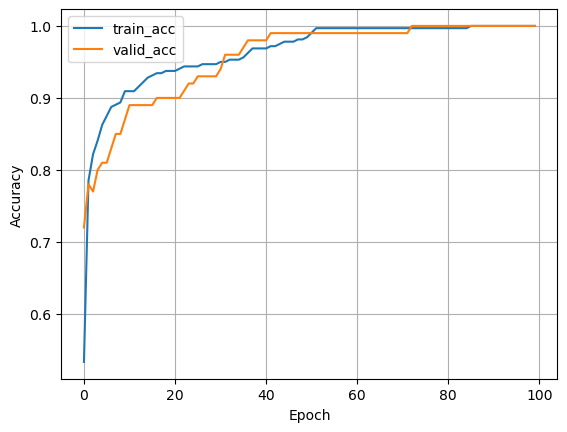
タスクが簡単だったこともあり,最終的に学習・検証データ共に100%の精度で分類できていることがわかった.タスクやデータセットによっては学習データの精度は1.0に近づくが,検証データの精度が徐々に低下していく減少が見られる.その場合は過学習が起こっていると分析でき,適切な正則化やハイパーパラメータの調整が必要となる.
識別境界の可視化#
識別境界を可視化するために,MLPを読み出そう.そのために,まずは保存したモデルと同じ構造を持つMLPのインスタンスを作成する.
import torch.nn as nn
class MLP(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MLP, self).__init__()
self.layer_in = nn.Linear(input_dim, hidden_dim)
self.layer_hidden = nn.Linear(hidden_dim, hidden_dim)
self.layer_out = nn.Linear(hidden_dim, output_dim)
self.act = nn.ReLU()
self.act_out = nn.Identity()
def forward(self, x):
h = x
h = self.layer_in(h)
h = self.act(h)
h = self.layer_hidden(h)
h = self.act(h)
h = self.layer_out(h)
h = self.act_out(h)
return h
model = MLP(input_dim=2, hidden_dim=32, output_dim=2)
load_state_dictでモデルインスタンスに重みを適用する.
import torch
save_path = 'output/model.pth'
model.load_state_dict(torch.load(save_path))
<All keys matched successfully>
Jupyter Notebookは異なるが同一のrandom_stateを指定することで再度可視化のためのテストデータを作成する.
from sklearn.datasets import make_moons
from sklearn.model_selection import train_test_split
X, y = make_moons(n_samples=500, noise=0.1, random_state=1234)
X_train, X_temp, y_train, y_temp = train_test_split(
X, y, test_size=0.4, random_state=1234)
X_val, X_test, y_val, y_test = train_test_split(
X_temp, y_temp, test_size=0.5, random_state=1234)
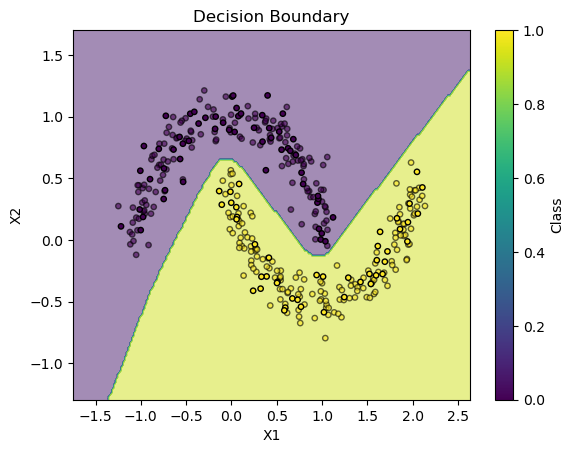
作成したデータセットと予測結果を元に識別境界を可視化する.
h = 0.02
x_min, x_max = X_train[:, 0].min() - 0.5, X_train[:, 0].max() + 0.5
y_min, y_max = X_train[:, 1].min() - 0.5, X_train[:, 1].max() + 0.5
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))
grid = np.c_[xx.ravel(), yy.ravel()]
grid = torch.tensor(grid, dtype=torch.float32)
model.eval()
with torch.no_grad():
pred = model(grid).argmax(dim=1).numpy()
pred = pred.reshape(xx.shape)
plt.contourf(xx, yy, pred, alpha=0.5)
plt.scatter(X_train[:, 0], X_train[:, 1], c=y_train, alpha=0.6, edgecolors="k", s=15)
plt.scatter(X_test[:, 0], X_test[:, 1], c=y_test, alpha=1.0, edgecolors="k", s=15)
plt.colorbar(label="Class")
plt.xlabel("X1")
plt.ylabel("X2")
plt.title("Decision Boundary")
plt.show()
特徴ベクトルの可視化#
入力が二次元の場合は各入力変数の予測の影響度を前述の可視化から解釈できる.しかしながら,入力が高次元になるとそのような分析が難しくなる.画像分類を例にすると,入力画像の解像度が \(100 \times 100\) である場合,入力次元は10,000次元となり,可視化が困難となる.
そのようなケースでは,モデル内部の特徴ベクトルの分布の可視化からの分析がよく用いられる.では,softmax関数が適用される前のモデルの出力値(ロジット)を取得してみよう.
まずは評価データセットをtorch.tensor形式の入力を作成する.
x = torch.from_numpy(X_test).to(torch.float32)
これを推論モードで伝播して,予測結果を得る.
model.eval()
logits = model(x)
行がサンプル数,列がクラス数(今回は2)の行列が得られるはずだ.これを散布図で可視化してみよう.
import matplotlib.pyplot as plt
logits = logits.detach().numpy()
plt.scatter(logits[:, 0], logits[:, 1], c=y_test, s=10)
plt.title("Logits of Moons Data")
plt.show();
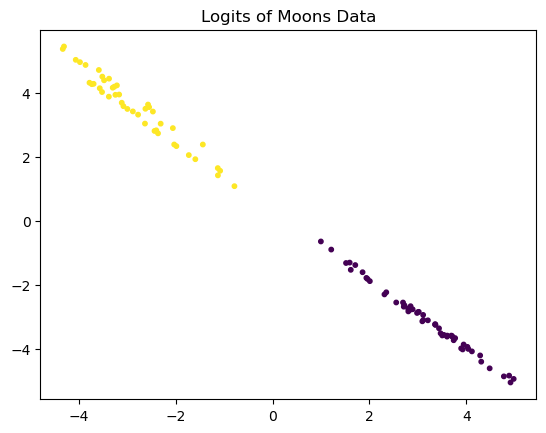
学習と評価のノートブックで同様の可視化を行なっているが,各データの分布が異なっていることがわかる.またクラスが分離された分布が学習できていることも確認できる.今回は2次元のため,このような可視化ができた.ロジットが多次元,つまり多クラス分類の場合はこのような可視化ができないことに注意されたい.その場合はt-SNEやPCAなどの次元削減手法を使って特徴空間の分離度合いを確認すると良い.
重みの可視化#
ニューラルネットワークには多数のパラメータが含まれているが,その分布や統計量をチェックすることで,学習状況を分析できる場合がある.ここでは,パラメータへのアクセス方法の復習として,線形層における重みパラメータの分布をヒストグラムで可視化する.
重みは次のように取得できる.
layer_hidden_weights = model.layer_hidden.weight.data.numpy()
print(layer_hidden_weights.shape)
print(layer_hidden_weights)
(32, 32)
[[ 0.05571872 -0.09549656 0.03489552 ... -0.15068069 -0.07545222
0.1218348 ]
[-0.07716247 0.18816704 0.05219263 ... 0.25439742 -0.01563637
0.19186494]
[ 0.07516072 -0.22570428 0.04447994 ... -0.09646136 0.03448362
-0.23371382]
...
[ 0.19115667 -0.07373201 0.17563564 ... -0.12706603 0.05922767
0.1531993 ]
[-0.13650472 0.18430217 0.1893012 ... 0.03400893 0.05305939
0.04370157]
[-0.04297358 0.11485431 0.17395073 ... 0.02113169 -0.06015217
-0.09259793]]
形状を確認してもわかる通り,行列形式になっているので,これをflatten()を使ってベクトル形式に変換する.
layer_hidden_weights = layer_hidden_weights.flatten()
print(layer_hidden_weights.shape)
(1024,)
これをmatplotlibで可視化する.
plt.hist(layer_hidden_weights, bins=20, edgecolor='k')
plt.title('Weight Distribution of layer_hidden')
plt.xlabel('Weight Values')
plt.ylabel('Frequency')
plt.show();
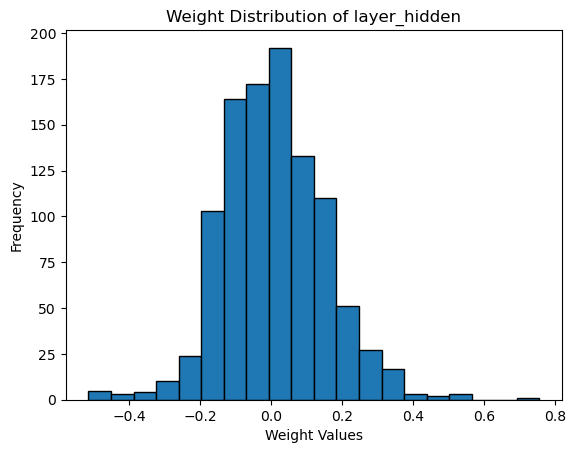
結果からもわかるように,0に近い重みが多く存在していることがわかる.過学習が起きている場合は,重みの値が大きくなるケースが多く,その傾向はこのような可視化から確認できる.
勾配の可視化#
同様の手順で勾配を可視化しよう.損失計算をして,backwardをすることで勾配を計算できる.
x = torch.from_numpy(X_test).to(torch.float32)
y = torch.from_numpy(y_test).to(torch.long)
loss_function = nn.CrossEntropyLoss()
output = model(x)
loss = loss_function(output, y)
loss.backward()
計算された勾配は次のようにして取得できる.
layer_hidden_grads = model.layer_hidden.weight.grad.numpy().flatten()
layer_hidden_grads
array([0., 0., 0., ..., 0., 0., 0.], dtype=float32)
重みと同様にヒストグラムとして可視化する.
plt.hist(layer_hidden_grads, bins=20, edgecolor='k')
plt.title('Gradient Distribution of layer_hidden')
plt.xlabel('Gradient Values')
plt.ylabel('Frequency')
plt.show();
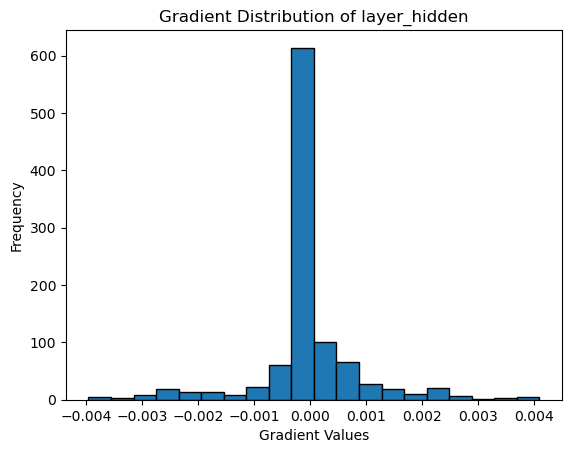
学習が完了していることは損失が変化しないので,勾配の分布が0に偏っている.学習に失敗する場合は,勾配の値が全て0もしくは,極端に大きな値を取っていることが多く,結果として勾配消失問題・勾配爆発問題が生ずる.また発展的な内容であるが,勾配のノルムが小さいほど,良い汎化が達成できていることを示す論文もあり,学習途中の勾配の推移を可視化することも有効である.