Self-Attention#
このノートブックでは,Transformerのコア要素である 自己注意機構(Self-Attention) について説明する.自己注意機構は自身のトークンと関連するトークンの情報を使って,自身のトークンの情報を強調したり,逆に減衰したり更新することができる仕組みである.そのため,自己注意機構内ではトークン間の類似度の計算と特徴の強調・減衰を行う加重和の計算が行われる.
Query, Key, Value#
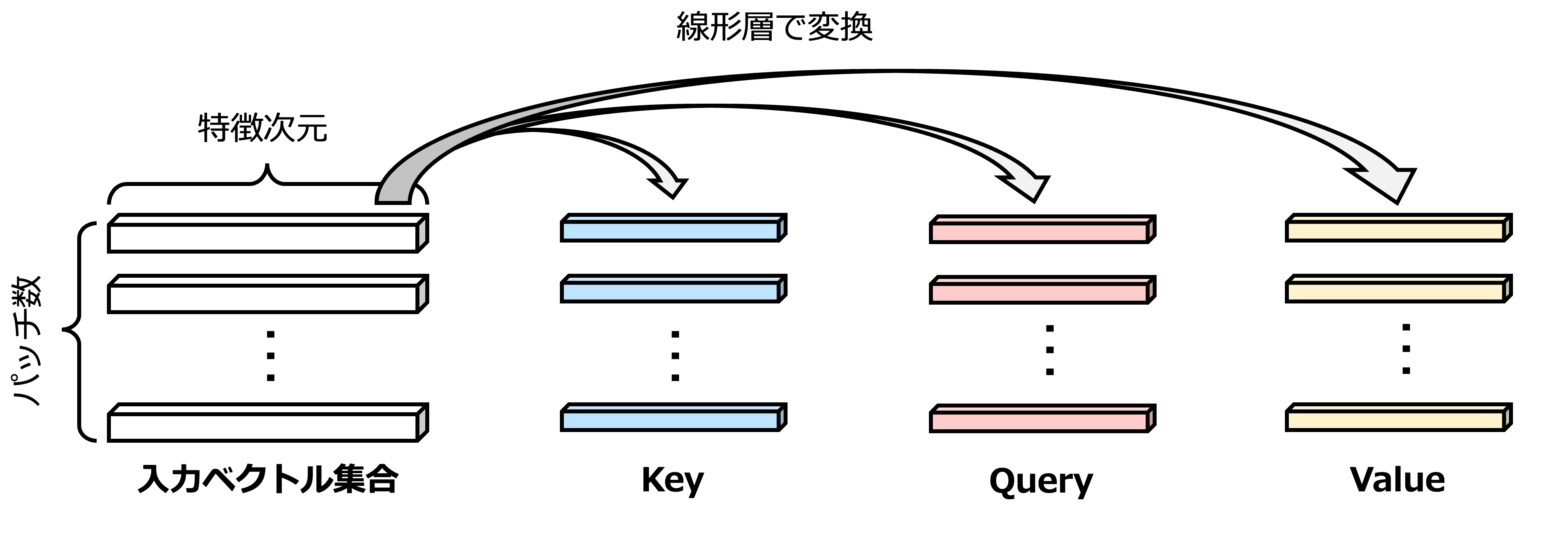
まず,Self-Attentionは,ある入力系列 \(\boldsymbol{X}=\left(\boldsymbol{x}_1, \boldsymbol{x}_2, \ldots, \boldsymbol{x}_N\right) \in \mathbb{R}^{N \times D}\) が与えられたとき,\(D\) 次元の各トークン \(\boldsymbol{x}_i\) は他のトークン \(\boldsymbol{x}_j\) と関連付けられる.具体的に,各トークン \(\boldsymbol{x}_i\) は Query(\(\boldsymbol{Q}\)),Key(\(\boldsymbol{K}\)),および Value(\(\boldsymbol{V}\))のベクトルに線形層によって次のようにマッピングされる.
ここで,\(D\) 次元から \(D'\) 次元へ変換する \(\boldsymbol{W}_Q\),\(\boldsymbol{W}_K\),\(\boldsymbol{W}_V\) はそれぞれの線形層の重み行列である.
それぞれの役割のイメージについて簡単に述べておこう.Query は他のトークンからどの情報を引き出すべきかを決定するための「質問」を表すベクトルである.各トークンが他のトークンに「何を求めているか」,つまりどのような情報を重視するかを示している.Key は各トークンが「どんな情報を持っているか」を示すベクトルであり,Queryからの質問に対する「鍵」を表す.Keyは各トークンが持つ情報の特徴を表しており,他のトークンが自身のQueryと照らし合わせたときに,関連性を評価する指標となっている.そして,Value は,実際に注意を向けるべき情報の内容を持つベクトルであり,各トークンが提供する「値」である.
では,この線形層の実装を行おう.まずはダミーの入力を作成する.
import torch
num_tokens = 10
embed_dims = 32
x = torch.randn((num_tokens, embed_dims))
print('x.shape:', x.shape)
x.shape: torch.Size([10, 32])
各線形層を次のように定義する.
import torch.nn as nn
proj_q = nn.Linear(embed_dims, embed_dims, bias=False)
proj_k = nn.Linear(embed_dims, embed_dims, bias=False)
proj_v = nn.Linear(embed_dims, embed_dims, bias=False)
線形層を適用して,Query(\(\boldsymbol{Q}\)),Key(\(\boldsymbol{K}\)),および Value(\(\boldsymbol{V}\))を計算する.
q = proj_q(x)
k = proj_k(x)
v = proj_v(x)
print('q.shape:', q.shape)
print('k.shape:', k.shape)
print('v.shape:', v.shape)
q.shape: torch.Size([10, 32])
k.shape: torch.Size([10, 32])
v.shape: torch.Size([10, 32])
類似度#
では,QueryとKeyの関連,つまり,質問に対するもっとも関連するトークンを求めたい.線形層によって変換されたQueryとKeyはそれぞれ \(N \times D'\) の行列であるので,それぞれの行列の \(i\) 番目と \(j\) 番目のトークン \(\boldsymbol{Q}_i\) と \(\boldsymbol{K}_j\) を考える.
これらのトークンはベクトルであるので,ベクトル間の類似度は一般的に,内積 もしくは コサイン類似度 を用いて計算される.内積を用いた類似度計算は,次のように表される.
ベクトル同士が同じ方向に向いている場合は大きな値,逆方向に向いている場合は小さな値(負の値)になる.そして,内積が0のときはベクトルが直交しており,ベクトル間が独立していることを示す.
また,ベクトルの長さ(ノルム)による影響を除くために,コサイン類似度を用いることが一般的である.コサイン類似度は以下のように定式化される.
コサイン類似度も内積と同様に値から類似度を解釈できる.
ViTでは内積を用いて類似度を計算する.QueryとKeyの全トークンに関する内積は次のように転置してから行列計算すれば各トークン間の関連を一つの行列にまとめることができる.
計算された Query(\(\boldsymbol{Q}\))とKey(\(\boldsymbol{K}\))の内積を上式から計算してみよう.
sim_mat = q @ k.T
print('sim_mat.shape:', sim_mat.shape)
sim_mat.shape: torch.Size([10, 10])
Attention Weight#
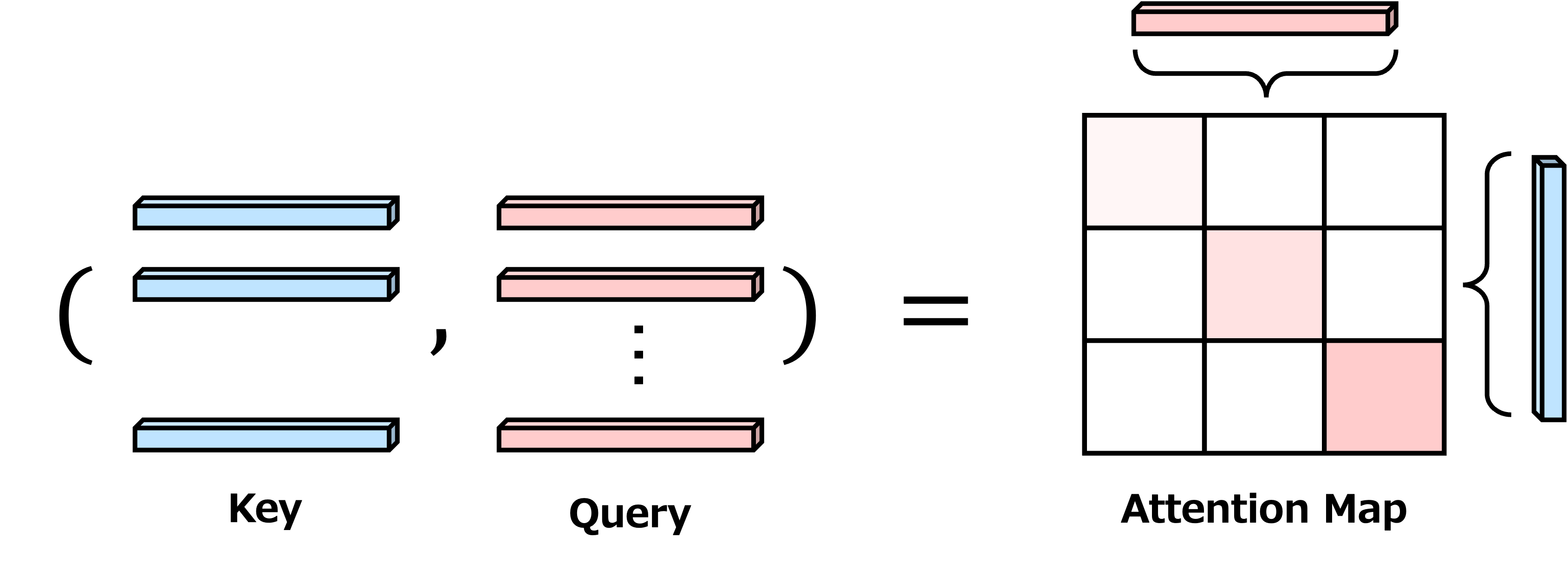
類似度計算から得られる類似度を表す行列は,この後Valueとの加重和を計算するので,次のようにsoftmax関数を適用してスケーリングとピークを持つような行列にする.
このとき,ベクトルの次元が大きくなるほど内積の値は大きくなるので,大きくなりすぎないように \(\sqrt{D'}\) で割っている.
では,このAttention Weightを実装しよう.
import torch.nn.functional as F
attn_weight = F.softmax((q @ k.T) * embed_dims ** -0.5, dim=1)
これをHeatmapとして可視化する.
import matplotlib.pyplot as plt
plt.imshow(attn_weight.detach().numpy(), cmap='hot')
plt.ylabel('Query')
plt.xlabel('Key')
plt.colorbar()
<matplotlib.colorbar.Colorbar at 0x1460470bd6d0>
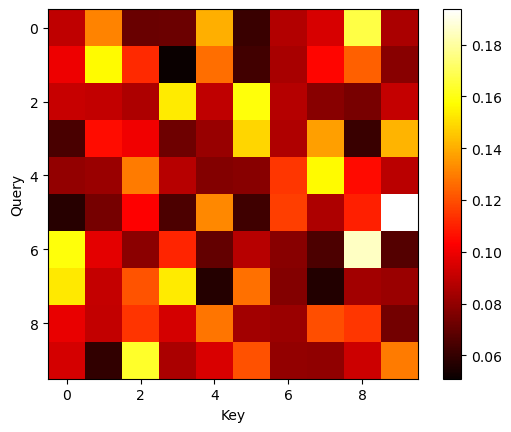
未学習なので適当な類似度が格納されたAttention Weightの可視化である点に注意されたいが,このような可視化からAttentionのイメージを掴んでもらえたらと思う.
加重和#

そして,このAttention Weightから実際に注意を向けるべき情報の内容を持つベクトル Value の値を取り出すために,次のように加重和を計算する.
上記は各トークンに対する処理であるが,以下のように行列計算もできる.
ここまでが1つのSelf-Attentionの処理となる.
これを実装すると次のようになる.
output = attn_weight @ v
print('output.shape:', output.shape)
output.shape: torch.Size([10, 32])
Multi-Head Self-Attentionを含むSelf-Attentionの実装#
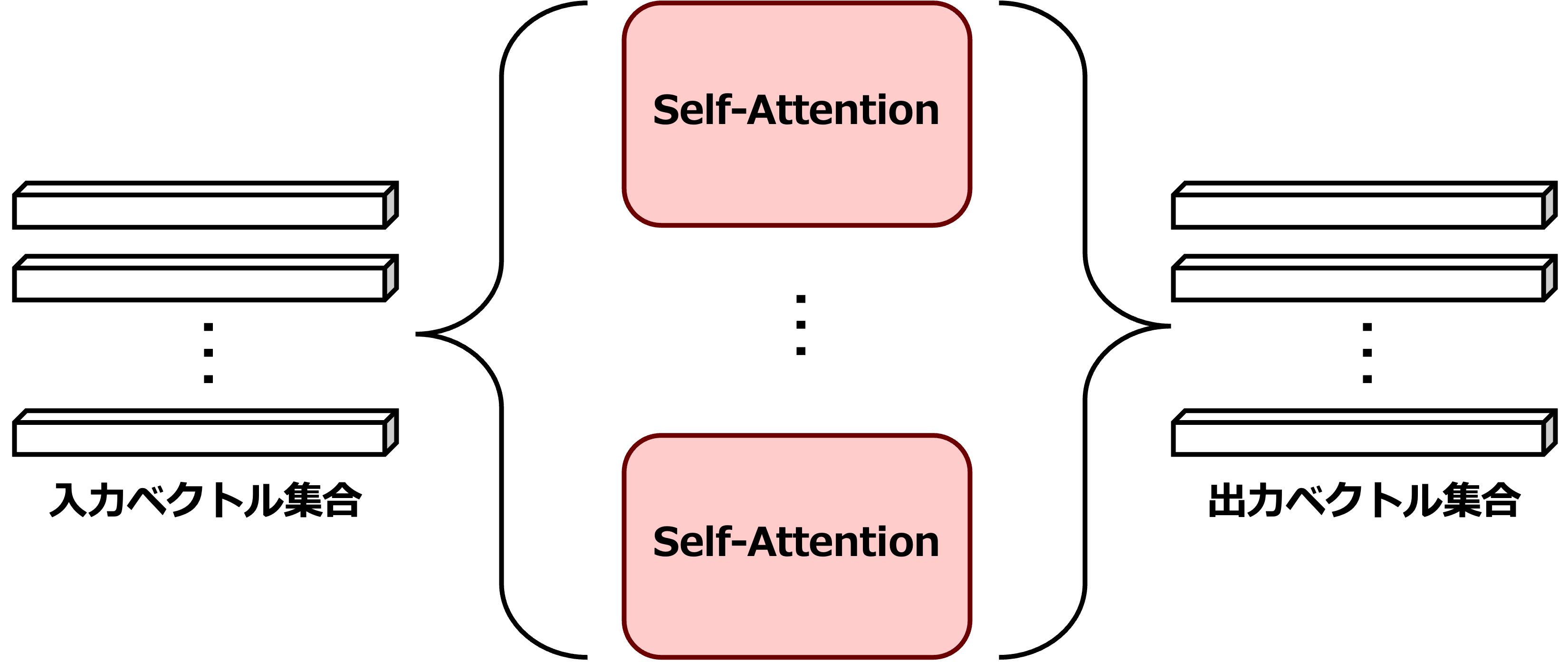
ここまでの処理の問題はsoftmaxを適用するため1つのトークンに対しておおよそ1つの値のピークしか生じないことである.また複数のAttentionがあるほうが直感的にも性能が上がりそうである.そしてこのSelf-Attentionを複数連ねたものが Multi-Head Self-Attention(MHSA) であり,異なる注意パターンを同時に学習できる.
MHSAの実装は \(D' = D_{head} * N_{head}\) というように設定すれば,次のように計算結果をヘッドの個数分だけ分割することで,複数のQuery,Key,Valueを用意できる.これを踏まえて,Self-Attention層としてPyTorchで実装する.
class Attention(nn.Module):
def __init__(self, dim, num_heads=4, dropout=0.5):
super().__init__()
self.head_dim = dim // num_heads
self.num_heads = num_heads
self.proj_q = nn.Linear(dim, dim, bias=False)
self.proj_k = nn.Linear(dim, dim, bias=False)
self.proj_v = nn.Linear(dim, dim, bias=False)
self.proj = nn.Linear(dim, dim, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
bs, num_tokens, dim = x.shape
q = self.proj_q(x)
k = self.proj_q(x)
v = self.proj_q(x)
q = q.reshape(bs, num_tokens, self.num_heads, self.head_dim)
k = k.reshape(bs, num_tokens, self.num_heads, self.head_dim)
v = v.reshape(bs, num_tokens, self.num_heads, self.head_dim)
attn_weight = q @ k.transpose(-2, -1) * dim ** -0.5
attn_weight = F.softmax(attn_weight, dim=-1)
attn_weight = self.dropout(attn_weight)
x = attn_weight @ v
x = x.transpose(1, 2).reshape(bs, num_tokens, dim)
x = self.proj(x)
x = self.dropout(x)
return x
bs = 1
num_tokens = 10
embed_dims = 32
x = torch.randn((bs, num_tokens, embed_dims))
attention = Attention(embed_dims)
y = attention(x)
print('y:', y.shape)
y: torch.Size([1, 10, 32])
そして,最終的に全てのヘッドの出力を結合した後,線形層とドロップアウトを適用することが多い.また,計算効率等を無視した非常に簡単な実装なので注意されたい.