学習と評価#
このノートブックでは,Vision Transformerの学習と評価を行うためのパイプラインを実装する.今回は,画像を直接入力できるように,かつ,ヘッドからの予測結果がCNNの形状と同じになるようにViTを実装したので,モデルの定義以外はCNNのコードをすべて流用できる.
そのため,CNNではMNISTを使ったが,今回はカラー画像のCIFAR10を利用して学習させてみよう.
データセットの準備#
CIFAR10は10クラスからなる一般物体の画像認識用データセットであり,各データはRGBの3チャネル持つ.CIFAR10もMNISTと同じように torchvision でサポートされており,次のように簡単に読み込むことができる.
import torchvision.transforms as transforms
import torchvision.datasets as datasets
dataset = datasets.CIFAR10(
root='./data', train=True, download=True,
transform=transforms.ToTensor())
Files already downloaded and verified
CIFAR10も初回実行時はrootにデータをダウンロードするため時間がかかる.正しくダウンロードできたならば,train=True としたので学習データセットが利用可能になる.
サンプル数と画像サイズをチェックする.
print('len(dataset):', len(dataset))
i = 0
x, y = dataset[i]
print('x.shape:', x.shape)
len(dataset): 50000
x.shape: torch.Size([3, 32, 32])
チャネル数が3チャネル,画像サイズが \(32 \times 32\) であることが確認できる.
データの最小値・最大値は
print('x.min():', x.min())
print('x.max():', x.max())
x.min(): tensor(0.)
x.max(): tensor(1.)
となり,ToTensor() を渡しているので0から1の間に正規化されている.ここでは,さらに 標準化(Standardization) を行おう.標準化はデータの平均を0,分散を1とする手法であり,ニューラルネットの学習においても性能改善のための重要なテクニックである.
各チャネルの平均と分散を計算しよう.内方表記を利用して学習データセットに含まれるデータを一度一つのテンソル化し,バッチ,幅,高さ方向に対して平均と標準偏差を次のように計算する.
import torch
data = torch.cat([d[0] for d in torch.utils.data.DataLoader(dataset)])
mean = data.mean(dim=[0, 2, 3])
std = data.std(dim=[0, 2, 3])
print('mean:', mean)
print('std:', std)
mean: tensor([0.4914, 0.4822, 0.4465])
std: tensor([0.2470, 0.2435, 0.2616])
計算できたので,これを使って標準化を行うtransformを作成する.今回は学習用にデータ拡張を施したtransformも作成しよう.またオリジナルのCIFAR10の解像度は確認した通り \(32 \times 32\) であるが,ViTへの入力(パッチ化)を考慮して,\(96 \times 96\) とする
img_size = 96
train_transform = transforms.Compose([
transforms.Resize(img_size),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean, std)])
test_transform = transforms.Compose([
transforms.Resize(img_size),
transforms.ToTensor(),
transforms.Normalize(mean, std)])
再度データセットを読み込んで学習・検証・評価データセットを作成する.
train_dataset = datasets.CIFAR10(
root='./data', train=True, download=True,
transform=train_transform)
train_size = int(len(train_dataset) * 0.9)
valid_size = int(len(train_dataset) * 0.1)
train_dataset, valid_dataset = \
torch.utils.data.random_split(
train_dataset, [train_size, valid_size])
test_dataset = datasets.CIFAR10(
root='./data', train=False, download=True,
transform=test_transform)
print(f'train data: {len(train_dataset)}')
print(f'validation data: {len(valid_dataset)}')
print(f'test data: {len(test_dataset)}')
Files already downloaded and verified
Files already downloaded and verified
train data: 45000
validation data: 5000
test data: 10000
データローダーを作成する.
from torch.utils.data import DataLoader
train_loader = DataLoader(train_dataset, batch_size=128)
valid_loader = DataLoader(valid_dataset, batch_size=100)
test_loader = DataLoader(test_dataset, batch_size=100)
ミニバッチを次のように取り出して,画像データを可視化しよう.ここで利用したtorchvision.utils.make_grid 関数はミニバッチの画像データの可視化の際に非常に便利である.
from torchvision.utils import make_grid
import matplotlib.pyplot as plt
x, y = next(iter(train_loader))
mean_ = torch.tensor(mean.numpy()).view(1, 3, 1, 1)
std_ = torch.tensor(std.numpy()).view(1, 3, 1, 1)
x = x * std_ + mean_
img = make_grid(x[:25], nrow=5)
plt.imshow(img.permute(1,2,0).numpy())
plt.axis('off')
(-0.5, 491.5, 491.5, -0.5)

以下の処理
mean_ = torch.tensor(mean.numpy()).view(1, 3, 1, 1)
std_ = torch.tensor(std.numpy()).view(1, 3, 1, 1)
x = x * std_ + mean_
は標準化の逆を行い,元の範囲に戻している.
モデルの定義#
データローダーが構築できたのでViTの構築を行う.行数が長くなるが,ViTのノートブックから必要な処理をコピペしている.
import torch
import torch.nn as nn
import torch.nn.functional as F
class MLP(nn.Module):
def __init__(self, dim, hidden_dim, dropout=0.):
super().__init__()
self.fc1 = nn.Linear(dim, hidden_dim)
self.act = nn.GELU()
self.fc2 = nn.Linear(hidden_dim, dim)
self.drop = nn.Dropout(dropout)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, num_heads=4, dropout=0.5):
super().__init__()
self.head_dim = dim // num_heads
self.num_heads = num_heads
self.proj_q = nn.Linear(dim, dim, bias=False)
self.proj_k = nn.Linear(dim, dim, bias=False)
self.proj_v = nn.Linear(dim, dim, bias=False)
self.proj = nn.Linear(dim, dim, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
bs, num_tokens, dim = x.shape
q = self.proj_q(x)
k = self.proj_q(x)
v = self.proj_q(x)
q = q.reshape(bs, num_tokens, self.num_heads, self.head_dim)
k = k.reshape(bs, num_tokens, self.num_heads, self.head_dim)
v = v.reshape(bs, num_tokens, self.num_heads, self.head_dim)
attn_weight = q @ k.transpose(-2, -1) * dim ** -0.5
attn_weight = F.softmax(attn_weight, dim=-1)
attn_weight = self.dropout(attn_weight)
x = attn_weight @ v
x = x.transpose(1, 2).reshape(bs, num_tokens, dim)
x = self.proj(x)
x = self.dropout(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, dropout):
super().__init__()
self.attn = Attention(dim, num_heads, dropout)
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.mlp = MLP(dim, dim, dropout)
def forward(self, x):
h = self.norm1(x)
h = self.attn(h)
h = x + h
h = self.norm2(h)
h = self.mlp(h)
h = x + h
return h
class Head(nn.Module):
def __init__(self, dim, num_classes):
super().__init__()
self.norm = nn.LayerNorm(dim)
self.fc = nn.Linear(dim, num_classes)
def forward(self, x):
x = self.norm(x)
x = self.fc(x)
return x
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=384):
super().__init__()
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class ViT(nn.Module):
def __init__(self, img_size, patch_size, in_channels, num_classes, embed_dim, num_heads, dropout):
super().__init__()
self.patch_embed = PatchEmbed(img_size, patch_size, in_channels, embed_dim)
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
num_patches = self.patch_embed.num_patches + 1
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
self.block1 = Block(embed_dim, num_heads, dropout)
self.block2 = Block(embed_dim, num_heads, dropout)
self.block3 = Block(embed_dim, num_heads, dropout)
self.head = Head(embed_dim, num_classes)
def forward(self, x):
x = self.patch_embed(x)
cls_tokens = self.cls_token.expand(x.shape[0], -1, -1)
x = torch.torch.cat((cls_tokens, x), dim=1)
x = self.block1(x)
x = self.block2(x)
x = self.block3(x)
x = self.head(x[:,0])
return x
インスタンス化を行う.
model = ViT(img_size, 16, 3, 10, 256, 4, 0.1)
print(model)
ViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 256, kernel_size=(16, 16), stride=(16, 16))
)
(block1): Block(
(attn): Attention(
(proj_q): Linear(in_features=256, out_features=256, bias=False)
(proj_k): Linear(in_features=256, out_features=256, bias=False)
(proj_v): Linear(in_features=256, out_features=256, bias=False)
(proj): Linear(in_features=256, out_features=256, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=256, out_features=256, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=256, out_features=256, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
)
(block2): Block(
(attn): Attention(
(proj_q): Linear(in_features=256, out_features=256, bias=False)
(proj_k): Linear(in_features=256, out_features=256, bias=False)
(proj_v): Linear(in_features=256, out_features=256, bias=False)
(proj): Linear(in_features=256, out_features=256, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=256, out_features=256, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=256, out_features=256, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
)
(block3): Block(
(attn): Attention(
(proj_q): Linear(in_features=256, out_features=256, bias=False)
(proj_k): Linear(in_features=256, out_features=256, bias=False)
(proj_v): Linear(in_features=256, out_features=256, bias=False)
(proj): Linear(in_features=256, out_features=256, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=256, out_features=256, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=256, out_features=256, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
)
(head): Head(
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=10, bias=True)
)
)
損失関数とオプティマイザの設定・GPUへの移動#
続いて,損失関数,オプティマイザを設定する.
from torch import optim
loss_function = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.1)
GPUへの移動も行う.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
ViT(
(patch_embed): PatchEmbed(
(proj): Conv2d(3, 256, kernel_size=(16, 16), stride=(16, 16))
)
(block1): Block(
(attn): Attention(
(proj_q): Linear(in_features=256, out_features=256, bias=False)
(proj_k): Linear(in_features=256, out_features=256, bias=False)
(proj_v): Linear(in_features=256, out_features=256, bias=False)
(proj): Linear(in_features=256, out_features=256, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=256, out_features=256, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=256, out_features=256, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
)
(block2): Block(
(attn): Attention(
(proj_q): Linear(in_features=256, out_features=256, bias=False)
(proj_k): Linear(in_features=256, out_features=256, bias=False)
(proj_v): Linear(in_features=256, out_features=256, bias=False)
(proj): Linear(in_features=256, out_features=256, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=256, out_features=256, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=256, out_features=256, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
)
(block3): Block(
(attn): Attention(
(proj_q): Linear(in_features=256, out_features=256, bias=False)
(proj_k): Linear(in_features=256, out_features=256, bias=False)
(proj_v): Linear(in_features=256, out_features=256, bias=False)
(proj): Linear(in_features=256, out_features=256, bias=False)
(dropout): Dropout(p=0.1, inplace=False)
)
(norm1): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(mlp): MLP(
(fc1): Linear(in_features=256, out_features=256, bias=True)
(act): GELU(approximate='none')
(fc2): Linear(in_features=256, out_features=256, bias=True)
(drop): Dropout(p=0.1, inplace=False)
)
)
(head): Head(
(norm): LayerNorm((256,), eps=1e-05, elementwise_affine=True)
(fc): Linear(in_features=256, out_features=10, bias=True)
)
)
学習・検証ループ#
こちらもCNNからの流用でコピペして実行する.
import numpy as np
def train_one_epoch(model, loader, loss_function, optimizer, device):
model.train()
train_loss, train_acc = [], []
for batch in loader:
x, y = batch
x, y = x.to(device), y.to(device)
optimizer.zero_grad()
output = model(x)
loss = loss_function(output, y)
loss.backward()
optimizer.step()
acc = (output.max(1)[1] == y).float().mean()
train_loss.append(loss.item())
train_acc.append(acc.item())
return np.mean(train_loss), np.mean(train_acc)
def test(model, loader, loss_function, device):
model.eval()
test_loss, test_acc = [], []
with torch.no_grad():
for batch in loader:
x, y = batch
x, y = x.to(device), y.to(device)
output = model(x)
loss = loss_function(output, y)
acc = (output.max(1)[1] == y).float().mean()
test_loss.append(loss.item())
test_acc.append(acc.item())
return np.mean(test_loss), np.mean(test_acc)
epochs = 10
train_loss, train_acc = [], []
valid_loss, valid_acc = [], []
for epoch in range(1, epochs+1):
print(f'Epoch {epoch}/{epochs}')
loss, acc = train_one_epoch(model, train_loader, loss_function, optimizer, device)
print(f'train_loss - {loss:.4f}, train_acc - {acc:.4f}')
train_loss.append(loss)
train_acc.append(acc)
loss, acc = test(model, valid_loader, loss_function, device)
print(f'valid_loss - {loss:.4f}, valid_acc - {acc:.4f}')
valid_loss.append(loss)
valid_acc.append(acc)
print('')
test_loss, test_acc = test(model, test_loader, loss_function, device)
print('test_loss = ', test_loss)
print('test_acc = ', test_acc)
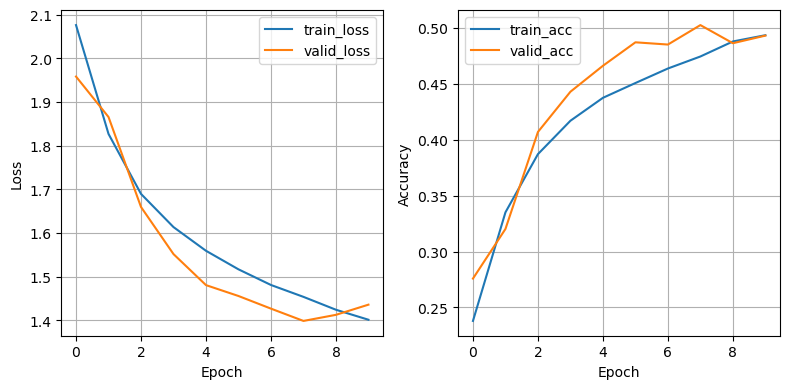
Epoch 1/10
train_loss - 2.0763, train_acc - 0.2379
valid_loss - 1.9584, valid_acc - 0.2758
Epoch 2/10
train_loss - 1.8271, train_acc - 0.3351
valid_loss - 1.8658, valid_acc - 0.3202
Epoch 3/10
train_loss - 1.6897, train_acc - 0.3872
valid_loss - 1.6597, valid_acc - 0.4070
Epoch 4/10
train_loss - 1.6137, train_acc - 0.4170
valid_loss - 1.5519, valid_acc - 0.4430
Epoch 5/10
train_loss - 1.5594, train_acc - 0.4375
valid_loss - 1.4808, valid_acc - 0.4662
Epoch 6/10
train_loss - 1.5169, train_acc - 0.4508
valid_loss - 1.4559, valid_acc - 0.4872
Epoch 7/10
train_loss - 1.4811, train_acc - 0.4638
valid_loss - 1.4269, valid_acc - 0.4852
Epoch 8/10
train_loss - 1.4539, train_acc - 0.4745
valid_loss - 1.3988, valid_acc - 0.5026
Epoch 9/10
train_loss - 1.4244, train_acc - 0.4880
valid_loss - 1.4128, valid_acc - 0.4864
Epoch 10/10
train_loss - 1.4015, train_acc - 0.4935
valid_loss - 1.4360, valid_acc - 0.4932
test_loss = 1.4268725216388702
test_acc = 0.49419998794794084
モデルサイズ,入力サイズ,GPUの性能によってこのセルの実行時間は異なるが,Block数を3に制限したとしても,学習にはCNN以上に時間がかかる.またViTは一般的に大規模なデータセットで事前学習を行う必要があり,パラメータを制限したとしても学習はCNNほど上手く進まない.
別ノートブックで事前学習済みモデルの利用方法についても紹介したい.
続いて,予測結果を出力する.
model.eval()
for batch in test_loader:
x, y = batch
x, y = x.to(device), y.to(device)
with torch.no_grad():
output = model(x)
_, prediction = torch.max(output, 1)
x = x.cpu()
mean_ = torch.tensor(mean.numpy()).view(1, 3, 1, 1)
std_ = torch.tensor(std.numpy()).view(1, 3, 1, 1)
x = x * std_ + mean_
x = x.permute(0,2,3,1)
fig, axes = plt.subplots(1, 10, figsize=(15, 2))
for i in range(10):
img = x[i].cpu().numpy().squeeze()
axes[i].imshow(img)
axes[i].set_title(f"Pred: {prediction[i].item()} - GT: {y[i].item()}")
axes[i].axis("off")
plt.tight_layout()
plt.show()
break

モデルの保存#
モデルを保存する.保存方法はこれまでと同様である.
import os
os.makedirs('output', exist_ok=True)
save_path = 'output/model.pth'
torch.save(model.state_dict(), save_path)
学習結果の表示と保存#
学習曲線の表示と結果の保存もこれまでと同様のコードで実行できる.
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.plot(train_loss, label='train_loss')
plt.plot(valid_loss, label='valid_loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.grid(True)
plt.subplot(1, 2, 2)
plt.plot(train_acc, label='train_acc')
plt.plot(valid_acc, label='valid_acc')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show();
np.savetxt('output/train_loss.txt', train_loss)
np.savetxt('output/train_acc.txt', train_acc)
np.savetxt('output/valid_loss.txt', valid_loss)
np.savetxt('output/valid_acc.txt', valid_acc)
注意:
Google Colabで実行している場合,保存したデータを自分のPCにダウンロードする必要がある.ダウンロードは画面左にあるフォルダアイコンをクリックすると保存されているデータが確認できる.各データをダウンロードしておこう.