Positional Embedding#
このノートブックでは,パッチ埋め込みで画像をテンソル化したことからもわかるように,このパッチが画像中のどこに位置しているか?という画像中の位置に関する情報がパッチ埋め込み化により欠落する.そこで,パッチに画像中の位置情報を付加するのが,位置埋め込み(Positional Embedding, PE)である.
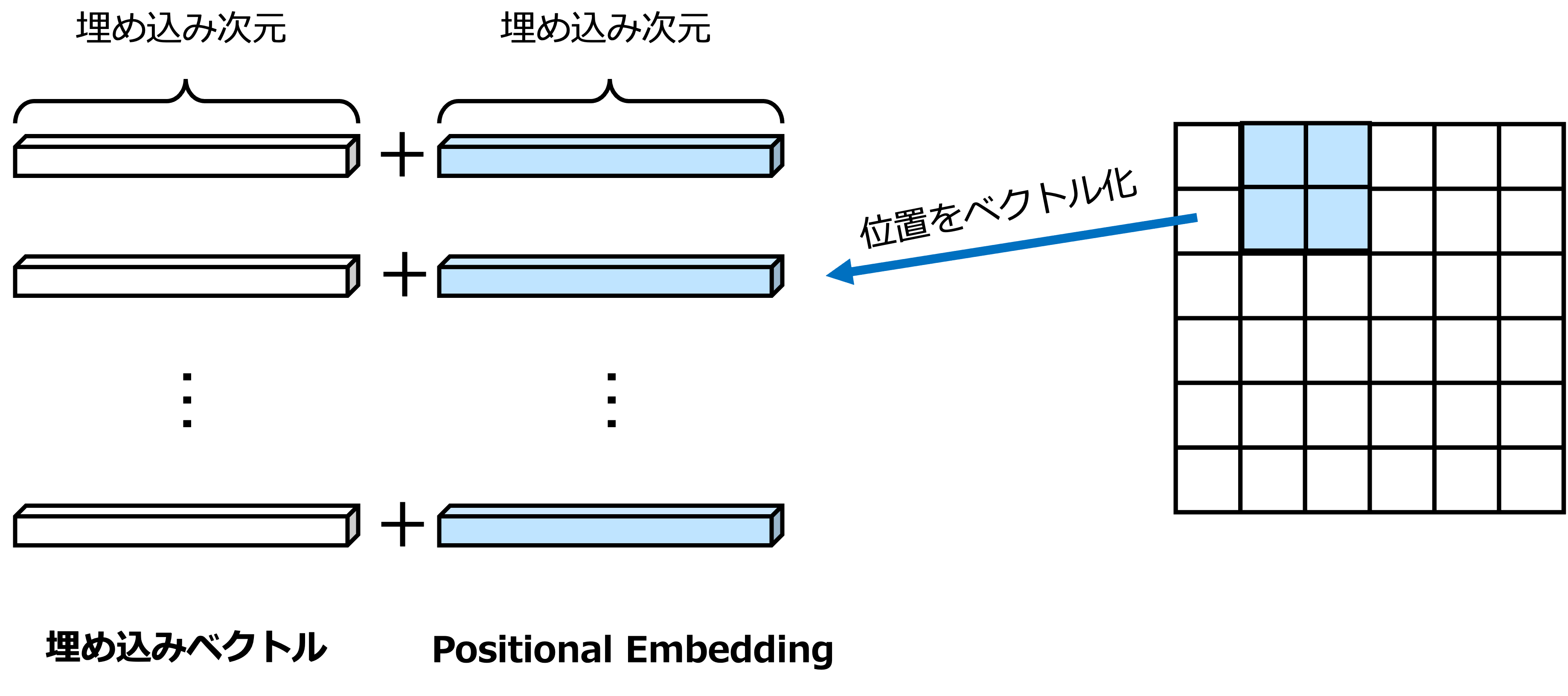
ViTで用いられるPEは学習可能なパラメータとして設定される埋め込み表現であり,PEをパッチに加算することで位置情報を付加する.まずは,パッチ埋め込み(ダミーデータ)を作成する.パッチ埋め込みは(ミニバッチサイズ,パッチ数,埋め込み次元)のテンソルであった.
import torch
import torch.nn as nn
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=384):
super().__init__()
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x).flatten(2).transpose(1, 2)
return x
patch_embed = PatchEmbed()
dummy_img = torch.randn((1, 3, 224, 224))
x = patch_embed(dummy_img)
print('x.shape:', x.shape)
x.shape: torch.Size([1, 196, 384])
そして,パッチ埋め込みに対して,クラストークンが結合される.
embed_dim = x.shape[2]
cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
bs = x.shape[0]
cls_tokens = cls_token.expand(bs, -1, -1)
x = torch.cat((cls_tokens, x), dim=1)
print('x.shape:', x.shape)
x.shape: torch.Size([1, 197, 384])
PEは学習可能なパラメータなので,nn.Module のパラメータであることを示す nn.Parameter を使って次のように実装する.クラストークンにも位置埋め込みは加算されるのでパッチ数には注意が必要である.
import torch
import torch.nn as nn
num_patches = x.shape[1]
embed_dim = x.shape[2]
pos_embed = nn.Parameter(torch.zeros(1, num_patches, embed_dim))
print('pos_embed.shape:', pos_embed.shape)
pos_embed.shape: torch.Size([1, 197, 384])
この pos_embed が損失の勾配から学習中に更新され,パッチの位置情報を獲得していく.
最終的に,ViTへ入力されるテンソルはクラストークン付きのパッチにPEを加算した次の入力である.
x = x + pos_embed
print('x.shape:', x.shape)
x.shape: torch.Size([1, 197, 384])
以上で,ViTへの入力の前処理が完了した.