Pooling層#
このノートブックでは,CNNの重要な構成要素の1つであるプーリング層(Pooling Layer)について説明する.プーリング層は,畳み込み層と組み合わせて用いられ,特徴マップのダウンサンプリングを行うことで計算効率の向上と特徴の位置不変性を実現する.プーリング層は,入力された特徴マップの空間的なサイズを縮小する操作を行う.具体的には,特徴マップの各領域から代表的な値を選択または計算することで,より小さな特徴マップを生成する.この操作によって,パラメータ数と計算量の削減,位置ズレに対する頑健性の向上などの利点がある.

Poolingの演算#
高さが \(H\) で幅が \(W\) のチャネル数 \(C\) の入力特徴マップ \(\boldsymbol{X} \in \mathbb{R}^{H \times W \times C}\) に対して,プーリング演算は以下のように定式化できる:
Poolingは,畳み込み層のように,固定のフィルタサイズ \(k\) で定義される局所領域をストライド \(s\) で走査しながら,その領域に対してPoolingは特定領域内の情報を集約する処理を行う.このような局所領域に対する演算であるが,畳み込みとは異なり,学習可能なパラメータを持たない.具体的に,関数 \(f_\mathrm{pool}\) は,各領域内の最大値を選択する処理(これを Max Pooling とよぶ)や領域内の平均値を選択する処理(これを Average Pooling とよぶ)をする.
Max Pooling#
最大値プーリング(Max Pooling) は各領域内の最大値を代表値として次の層へ伝播する.
具体例として,\(4 \times 4\) の入力特徴マップ \(\boldsymbol{X}\) に対して,\(2 \times 2\) のウィンドウサイズでストライド2のMax Poolingを適用する例を考える.
この入力に対してMax Poolingを適用すると次のようになる(Poolingの領域を色で示した).
例えば,左上 \((i,j)=(1,1)\) の場合,\(\boldsymbol{H}_{1,1} = \max (1,3,2,1) = 3\) という計算をしている.
MaxPoolingは次のように利用できる.
import torch
import torch.nn as nn
x = torch.tensor([
[1, 3, 2, 5],
[2, 1, 4, 2],
[5, 2, 3, 1],
[1, 3, 2, 4]
], dtype=torch.float32)
x = x.unsqueeze(0).unsqueeze(0)
max_pool = nn.MaxPool2d(kernel_size=2, stride=2)
h = max_pool(x)
print('x.shape:', x.shape)
print(x)
print('h.shape:', h.shape)
print(h)
x.shape: torch.Size([1, 1, 4, 4])
tensor([[[[1., 3., 2., 5.],
[2., 1., 4., 2.],
[5., 2., 3., 1.],
[1., 3., 2., 4.]]]])
h.shape: torch.Size([1, 1, 2, 2])
tensor([[[[3., 5.],
[5., 4.]]]])
Average Pooling#
平均値プーリング(Average Pooling) は各領域内の平均値を代表値として次の層へ伝播する.
Max Poolingと同じ \(4 \times 4\) の入力特徴マップ \(\boldsymbol{X}\) に対して,\(2 \times 2\) のウィンドウサイズでストライド2のAverage Poolingを適用すると次のようになる.
例えば,左上 \((i,j)=(1,1)\) の場合,\(\boldsymbol{H}_{1,1} = (1+3+2+1)/4 = 1.75\) という計算をしている.
Average PoolingはPyTorchで次のように利用できる.
avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
h = avg_pool(x)
print('x.shape:', x.shape)
print(x)
print('h.shape:', h.shape)
print(h)
x.shape: torch.Size([1, 1, 4, 4])
tensor([[[[1., 3., 2., 5.],
[2., 1., 4., 2.],
[5., 2., 3., 1.],
[1., 3., 2., 4.]]]])
h.shape: torch.Size([1, 1, 2, 2])
tensor([[[[1.7500, 3.2500],
[2.7500, 2.5000]]]])
Global Average Pooling#
主に分類タスクにおけるCNNの最後の畳み込み層の出力を線形層に入力する前に使用されるPoolingとして,Global Average Pooling がある.通常,畳み込みから線形層への変換は,画像で扱ったように,
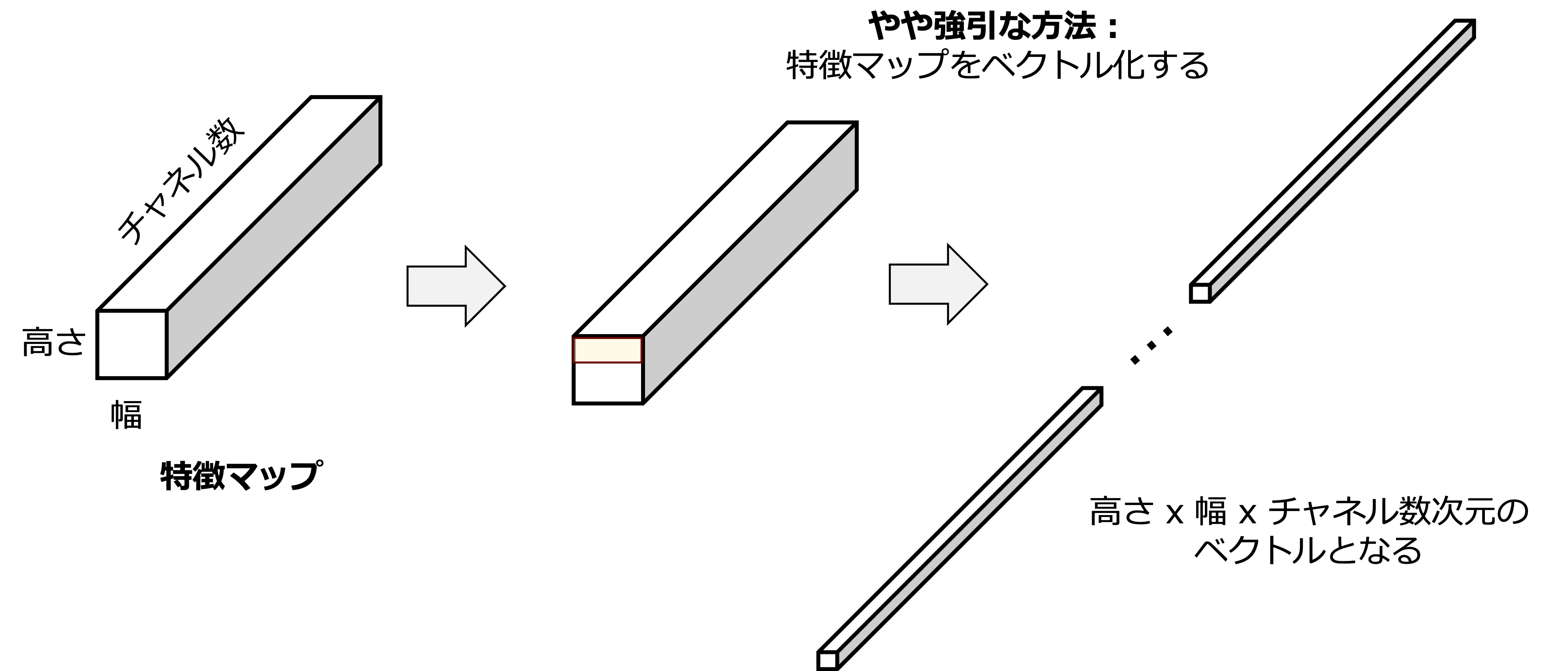
と解像度に依存するFlatten処理がシンプルな実装として考えることができる.GAPはこれを解像度に依存せずに変換できる.まずこの処理は,特徴マップ全体に対して一つの値を計算する.
これにより,例えば,特徴マップ \(\boldsymbol{X} \in \mathbb{R}^{H \times W \times C}\) をチャネル数の次元を持つベクトル \(\boldsymbol{X}'\in \mathbb{R}^{C}\) に変換できる.これによって Flatten などを利用せずとも,特徴マップをベクトル化できる.
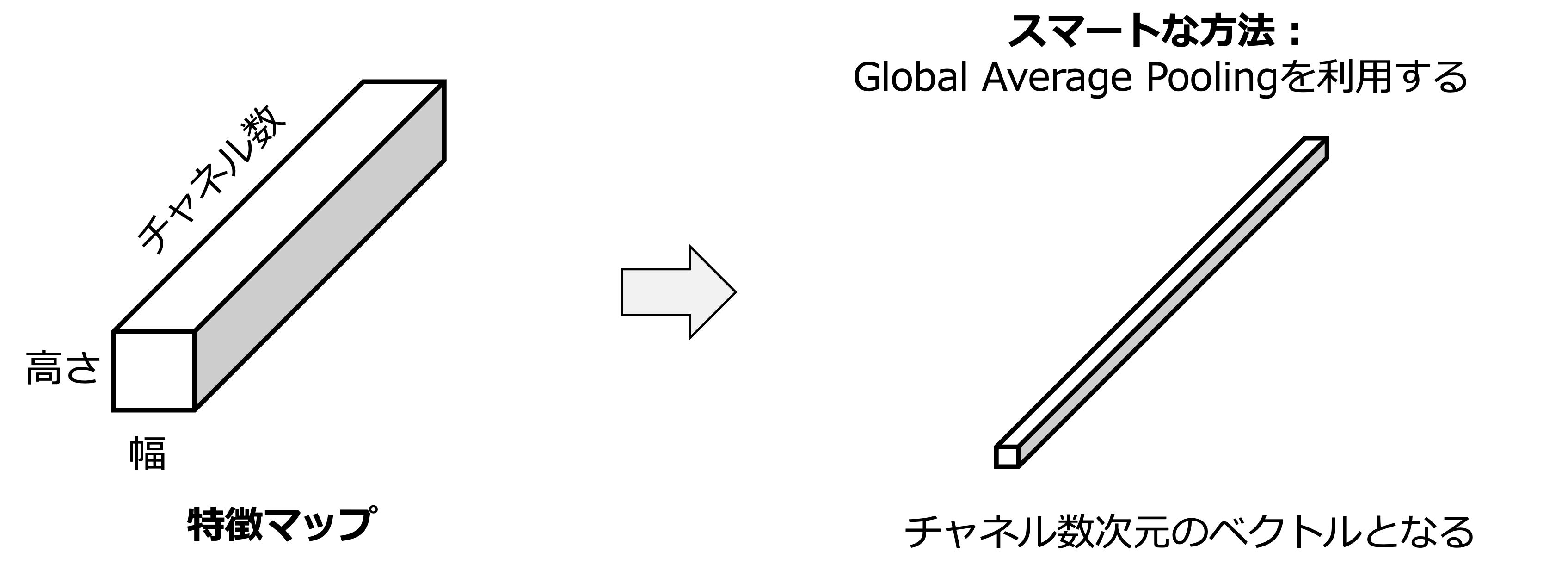
平均の代わりに最大値を取る Global Max Pooling もあるが,平均化の方が一般的である.
Max Poolingと同じ \(4 \times 4\) の入力特徴マップ \(\boldsymbol{X}\) に対して,\(2 \times 2\) のウィンドウサイズでストライド2のGlobal Average Poolingを適用すると次のようになる.
Global Average PoolingはPyTorchで次のように利用できる.
global_avg_pool = nn.AdaptiveAvgPool2d(output_size=(1, 1))
h = global_avg_pool(x)
print('x.shape:', x.shape)
print(x)
print('h.shape:', h.shape)
print(h)
x.shape: torch.Size([1, 1, 4, 4])
tensor([[[[1., 3., 2., 5.],
[2., 1., 4., 2.],
[5., 2., 3., 1.],
[1., 3., 2., 4.]]]])
h.shape: torch.Size([1, 1, 1, 1])
tensor([[[[2.5625]]]])