パッチ埋め込み#
このノートブックでは,Vision Transformer (ViT)における入力画像の パッチ化(Patch) と パッチ埋め込み(Patch Embedding) について説明する.パッチ化とは,下図のように入力画像を局所領域単位でクロップする処理である.そしてパッチ埋め込みとはそのパッチをベクトル化する処理である.
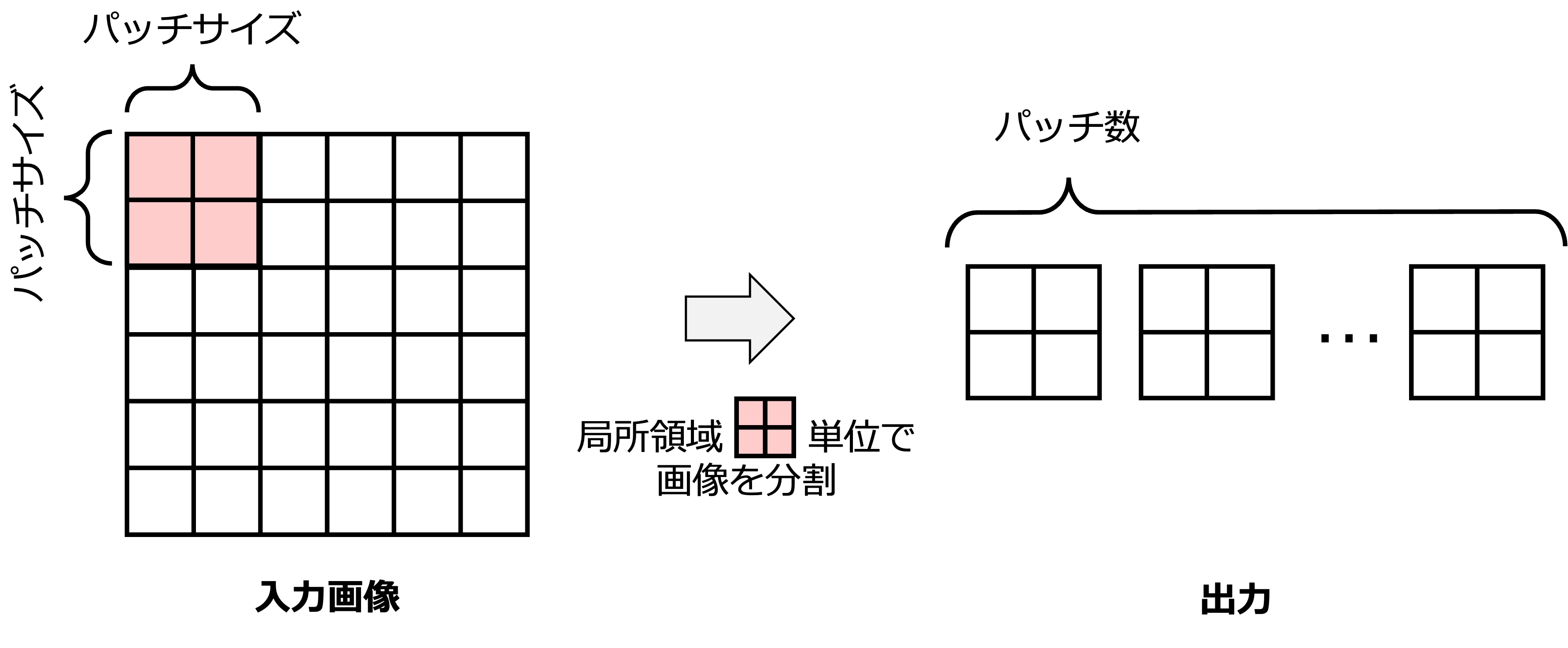
パッチの局所領域は例えば \(16 \times 16\) のサイズである.CNNが主流であったコンピュータビジョン分野では,画素間の関連を捉えるために畳み込み演算が主流であり,自然言語のような単語の区切りを局所領域ごとでクロップすることで処理するパッチ化はかなり異質な処理であった.しかしながら,1枚の画像を例えば \(256(=16 \times 16)\) のパッチにしてしまっても,CNNモデルよりもこのようなパッチに基づいて特徴抽出処理を行うViTの性能が優れていることが報告されている.その高い性能からも,近年ではViTは標準的な画像分類モデルとなっている.
ここでは,このパッチ化について,まずパッチ化された画像の可視化,パッチ化とパッチ埋め込みの実装の順で説明する.
パッチ化された画像#
ここでは,\(224 \times 224\) サイズの画像が与えられ,これを \(16 \times 16\) のサイズの局所領域のパッチを作成する.作成されるパッチの数は高さが \(224 / 16 = 14\) に分割,幅も \(224 / 16 = 14\) に分割されるので,計 \(14 \times 14 = 196\) 個のパッチが生成される.
まずは scikit-learn にある画像データを読み込み,PIL 形式に変換する.
from skimage import data
from PIL import Image
img = data.astronaut()
img = Image.fromarray(img)
print('img.size:', img.size)
img
img.size: (512, 512)

画像サイズとデータ型を transform で変換する.
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor()
])
img_tensor = transform(img).unsqueeze(0)
print('img_tensor.shape:', img_tensor.shape)
img_tensor.shape: torch.Size([1, 3, 224, 224])
続いて,テンソルを小さなパッチに分割する unfold 関数を用いてパッチ化を行う.ここではパッチ化された領域が重複しないようにパッチのウィンドウを stride=16 を設定して実行する.
patch_size = 16
stride = 16
bs, c, h, w = img_tensor.shape
patches = img_tensor.unfold(2, patch_size, stride).unfold(3, patch_size, stride)
print('pathes.shape:', patches.shape)
pathes.shape: torch.Size([1, 3, 14, 14, 16, 16])
正しく実行できると,(バッチサイズ,チャネル,パッチ数,パッチ数,パッチサイズ,パッチサイズ)の6階テンソルへ変形される.これを可視化するために,パッチの軸を(バッチサイズ,パッチ数,パッチ数,パッチサイズ,パッチサイズ,チャネル数)というCNNへの入力のような形状に変換する.
num_h = patches.shape[2]
num_w = patches.shape[3]
patches = patches.permute([0, 2, 3, 4, 5, 1])
print('pathes.shape:', patches.shape)
pathes.shape: torch.Size([1, 14, 14, 16, 16, 3])
そして,次のようにmatplotlibで可視化する.
import matplotlib.pyplot as plt
patches = patches[0].numpy()
fix, axes = plt.subplots(num_h, num_w, figsize=(6, 6))
for i in range(num_h):
for j in range(num_w):
axes[i,j].imshow(patches[i,j])
axes[i,j].axis('off')

ViTではこのパッチ化がまず入力画像に対して行われる処理となる.
unfold 関数の補足#
unfold 関数は指定した軸に対して,ウィンドウサイズとストライドから分割する処理である.次のサンプルコードで確認されたい.
import torch
x = torch.arange(16).view(4, 4)
print(f'x: \n{x}')
unfolded_x = x.unfold(0, 2, 2).unfold(1, 2, 2)
print(f'unfolded_x: \n{unfolded_x}')
x:
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15]])
unfolded_x:
tensor([[[[ 0, 1],
[ 4, 5]],
[[ 2, 3],
[ 6, 7]]],
[[[ 8, 9],
[12, 13]],
[[10, 11],
[14, 15]]]])
パッチ埋め込み#
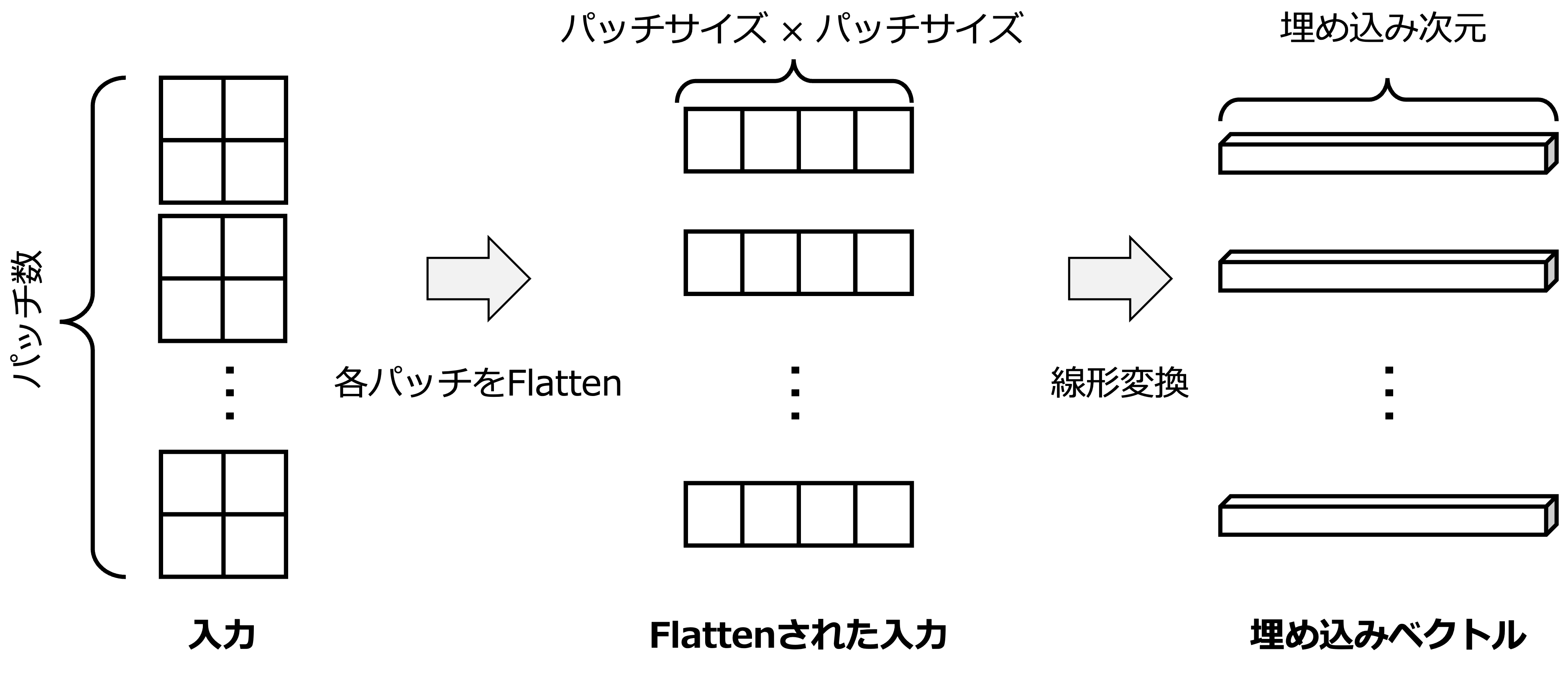
パッチ埋め込みは上記のパッチをベクトル化して,そのベクトルを線形層などで固定長のベクトルに変換する処理である.愚直に実装するならば,可視化の際に変形した各パッチに対して線形層を適用して,再度パッチの形状に戻せば良い.しかし,このパッチ埋め込みはパッチサイズをフィルタサイズとした畳み込み層を活用するとスマートに実装できる.
以下のセルはパッチ埋め込みを行うPatchEmbed層である.
import torch.nn as nn
class PatchEmbed(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=384):
super().__init__()
self.num_patches = (img_size // patch_size) * (img_size // patch_size)
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x).flatten(2).transpose(1, 2)
return x
可視化の際に作成した img_tensor を伝播してみる.
patch_embed = PatchEmbed()
patches = patch_embed(img_tensor)
print('patches.shape:', patches.shape)
patches.shape: torch.Size([1, 196, 384])
(ミニバッチサイズ,パッチ数,埋め込み次元)の入力テンソルが得られた.線形層を伝播しているため,可視化はできない点に注意されたい.
クラストークン#
ViTでは,分類タスクを解く際,分類用の特別なトークンである クラストークン(Class Token) をパッチに付与する.このトークンは分類用の線形層に入力され,分類損失の勾配が直接流れるトークンである.CNNとは異なる分類方法であるが,自然言語処理分野で登場した Transformer モデルの名残りであり,クラストークンが必要かという点など様々な議論が行われている.
クラストークン自体は追加のパッチとして考えれば容易に実装できる.
embed_dim = patches.shape[2]
cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
ここで,クラストークンは学習中に更新が行われるので,nn.Module のパラメータであることを示す nn.Parameter を使ってパラメータ化している.
そして,このクラストークンは patches に追加のパッチとして結合されるが,patches はミニバッチサイズだけサンプルがあるので,それぞれのサンプルに同一のクラストークンを結合する必要がある.これは次のように .expand と .cat を利用すれば良い.
bs = patches.shape[0]
cls_tokens = cls_token.expand(bs, -1, -1)
x = torch.cat((cls_tokens, patches), dim=1)
print('x.shape:', x.shape)
x.shape: torch.Size([1, 197, 384])
パッチ数が +1 されていることがわかるだろう.
そして,このパッチに対して位置埋め込み(Positional Embedding)を足し合わせ,クラス分類用のトークン(Class Token)を追加することでViTへの入力表現が完成する.
expand の補足#
expand は1次元の軸を複製して拡張したテンソルを作成する処理である.次のセルで挙動を確認されたい.
x = torch.tensor([[1, 2, 3]])
print(f'x: \n{x}')
x_ = x.expand(3, 3)
print(f'expanded_x: \n{x_}')
x:
tensor([[1, 2, 3]])
expanded_x:
tensor([[1, 2, 3],
[1, 2, 3],
[1, 2, 3]])
cat の補足#
cat は指定した軸が揃った複数のテンソルを結合する処理である.次のセルで挙動を確認されたい.
a = torch.tensor([[1, 2], [3, 4]])
b = torch.tensor([[5, 6], [7, 8]])
print(f'a: \n{a}')
print(f'b: \n{b}')
c = torch.cat((a, b), dim=0)
print(f'c: \n{c}')
d = torch.cat((a, b), dim=1)
print(f'd: \n{d}')
a:
tensor([[1, 2],
[3, 4]])
b:
tensor([[5, 6],
[7, 8]])
c:
tensor([[1, 2],
[3, 4],
[5, 6],
[7, 8]])
d:
tensor([[1, 2, 5, 6],
[3, 4, 7, 8]])